In the rapidly evolving landscape of data driven decision making, two roles have emerged as critical pillars of modern organizations: data engineers and data scientists. While both professionals work with data, their responsibilities, skill sets, and career trajectories differ significantly. Understanding these distinctions is essential for businesses building data teams and professionals charting their career paths in 2025’s competitive tech landscape
The data economy is booming. Companies worldwide are investing billions in data infrastructure and analytics capabilities, creating unprecedented demand for skilled professionals who can transform raw data into actionable insights. Yet, confusion persists about the fundamental differences between data engineering and data science roles. This comprehensive guide will clarify these distinctions, explore career opportunities, and help you determine which path aligns with your goals.
Key Takeaways
- Data engineers build and maintain the infrastructure that enables data collection, storage, and processing, while data scientists analyze data to extract insights and build predictive models
- Data engineering focuses on creating robust data pipelines and ensuring data quality, whereas data science emphasizes statistical analysis, machine learning, and business intelligence
- Career paths differ significantly: data engineering jobs typically require strong software engineering skills, while data science positions demand advanced statistical and mathematical knowledge
- Both roles are complementary and essential for successful data driven organizations, with data engineers providing the foundation that data scientists build upon
- Salary and demand remain strong for both positions in 2025, with data engineering experiencing particularly rapid growth as organizations prioritize data infrastructure
Understanding the Data Landscape in 2025
The data industry has matured significantly over the past decade. What began as relatively undefined roles have evolved into distinct career paths with specialized skills, tools, and responsibilities. Organizations now recognize that big data initiatives require both engineering excellence and analytical expertise to succeed.
The volume, velocity, and variety of data continue to expand exponentially. Companies collect information from countless sources customer interactions, IoT devices, social media, transaction systems, and more. This data deluge has created two fundamental challenges that data engineers and data scientists address from different angles:
- Infrastructure Challenge: How do we reliably collect, store, process, and serve massive amounts of data?
- Insights Challenge: How do we extract meaningful patterns and predictions from this data?
Data engineers tackle the first challenge, while data scientists focus on the second. Both roles have become indispensable as artificial intelligence transforms modern businesses and data-driven strategies become competitive necessities.
What is Data Engineering?
Data engineering is the discipline of designing, building, and maintaining the systems and architecture that enable data generation, storage, and analysis. Data engineers are the architects and construction workers of the data world they create the foundation upon which all data initiatives rest.
Core Responsibilities of Data Engineers
Data engineers wear many hats, but their primary responsibilities include:
- Building Data Pipelines: Creating automated workflows that extract data from various sources, transform it into usable formats, and load it into storage systems (ETL/ELT processes)
- Database Management: Designing and optimizing databases, data warehouses, and data lakes to ensure efficient storage and retrieval
- Infrastructure Maintenance: Monitoring data systems, troubleshooting issues, and ensuring high availability and performance
- Data Security: Implementing security measures to protect sensitive information and ensure compliance with regulations
- Data Quality Assurance: Establishing processes to validate data accuracy, completeness, and consistency
- Performance Optimization: Tuning queries, indexes, and infrastructure to handle growing data volumes efficiently
Essential Skills for Data Engineering
Success in data engineering requires a diverse technical skill set:
Programming Languages:
- Python (most common for data pipelines and automation)
- Java or Scala (especially for big data frameworks)
- SQL (essential for database interactions)
- Bash/Shell scripting (for automation)
Technologies and Tools:
- Big Data Frameworks: Apache Spark, Hadoop, Kafka
- Cloud Platforms: AWS (Redshift, S3, Glue), Google Cloud (BigQuery), Azure (Data Factory)
- Databases: PostgreSQL, MySQL, MongoDB, Cassandra
- Data Warehouses: Snowflake, Redshift, BigQuery
- Orchestration Tools: Apache Airflow, Luigi, Prefect
- Containerization: Docker, Kubernetes
Conceptual Knowledge:
- Distributed systems architecture
- Data modeling and schema design
- Stream processing vs. batch processing
- Data governance and compliance
- DevOps best practices
The Data Engineer’s Daily Work
A typical day for a data engineer might involve:
- Reviewing monitoring dashboards to identify pipeline failures or performance issues
- Writing code to build a new data pipeline connecting a recently acquired data source
- Optimizing a slow running query that’s impacting business reporting
- Collaborating with data scientists to understand their data requirements
- Implementing data quality checks to prevent bad data from entering the warehouse
- Participating in architecture discussions about scaling the data infrastructure
What is Data Science?
Data science is the practice of extracting knowledge and insights from data using statistical methods, machine learning algorithms, and domain expertise. Data scientists are the explorers and storytellers of the data world—they uncover hidden patterns and translate findings into business value.
Core Responsibilities of Data Scientists
Data scientists focus on analytical and predictive tasks:
- Exploratory Data Analysis: Investigating datasets to understand patterns, anomalies, and relationships
- Statistical Modeling: Applying statistical techniques to test hypotheses and quantify uncertainty
- Machine Learning: Building predictive models using supervised and unsupervised learning algorithms
- Data Visualization: Creating compelling visual representations of data and insights
- Business Intelligence: Translating data findings into actionable business recommendations
- Experimentation: Designing and analyzing A/B tests and other experiments
- Feature Engineering: Creating meaningful variables from raw data to improve model performance
Essential Skills for Data Science
Data scientists need a different skill mix compared to data engineers:
Programming and Tools:
- Python (with libraries like pandas, NumPy, scikit-learn, TensorFlow)
- R (for statistical analysis)
- SQL (for data extraction)
- Jupyter Notebooks or similar environments
- Visualization tools (Tableau, Power BI, matplotlib, Plotly)
Mathematical and Statistical Knowledge:
- Probability and statistics
- Linear algebra and calculus
- Hypothesis testing
- Regression analysis
- Time series analysis
- Bayesian methods
Machine Learning Expertise:
- Supervised learning (classification, regression)
- Unsupervised learning (clustering, dimensionality reduction)
- Deep learning and neural networks
- Natural language processing
- Computer vision
- Model evaluation and validation
Business Acumen:
- Domain knowledge in relevant industries
- Communication and storytelling skills
- Problem formulation and critical thinking
- Understanding of business metrics and KPIs
The Data Scientist’s Daily Work
A data scientist’s day might include:
- Analyzing customer churn patterns to identify at-risk segments
- Building a recommendation engine using collaborative filtering
- Creating visualizations for an executive presentation
- Tuning hyperparameters to improve model accuracy
- Collaborating with product teams to define success metrics for a new feature
- Conducting statistical analysis to evaluate the results of a marketing experiment
- Researching new AI and generative AI applications relevant to business challenges
Data Engineering vs Data Science: Side by Side Comparison
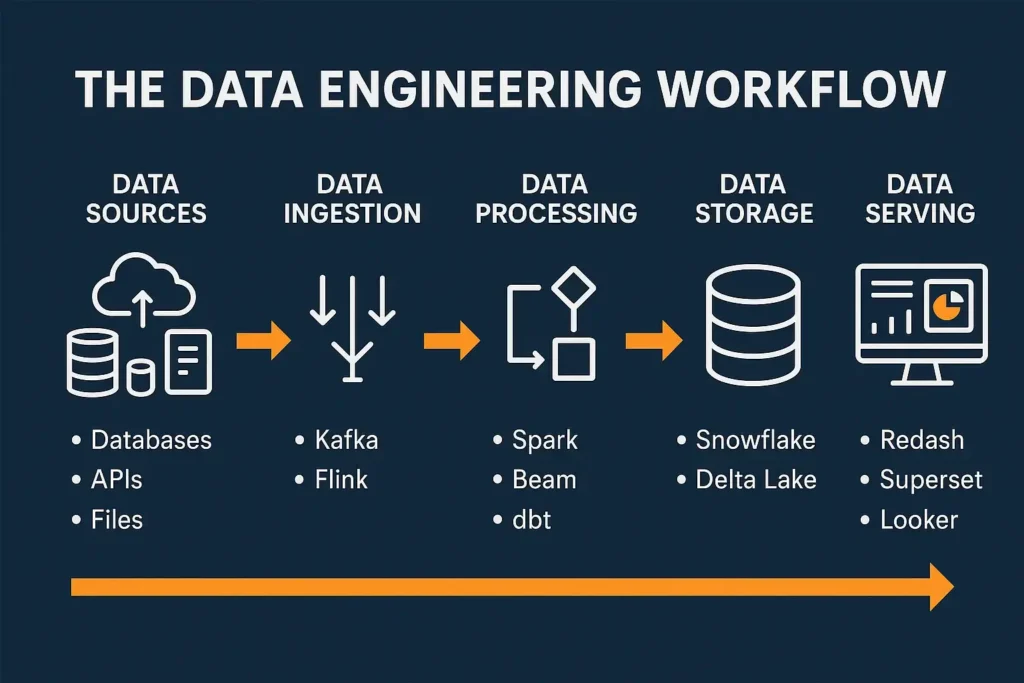
To clarify the distinctions between these roles, let’s examine them across multiple dimensions:
| Aspect | Data Engineering | Data Science |
| Primary Focus | Building data infrastructure and pipelines | Analyzing data and building predictive models |
| Main Output | Reliable, scalable data systems | Insights, predictions, and recommendations |
| Technical Emphasis | Software engineering, systems architecture | Statistics, mathematics, machine learning |
| Tools & Technologies | Spark, Kafka, Airflow, SQL, cloud platforms | Python, R, scikit learn, TensorFlow, visualization tools |
| Problem Type | “How do we collect, store, and serve this data?” | “What does this data tell us and what will happen next?” |
| Collaboration | Works with data scientists, analysts, and DevOps | Works with business stakeholders, product teams, and data engineers |
| Success Metrics | Data availability, pipeline reliability, query performance | Model accuracy, business impact, insight quality |
| Career Background | Often from software engineering or systems administration | Often from mathematics, statistics, or research |
| Typical Projects | Building ETL pipelines, optimizing databases, implementing data lakes | Customer segmentation, churn prediction, recommendation systems |
The Relationship Between Data Engineers and Data Scientists
While data engineering and data science are distinct disciplines, they’re deeply interconnected. Think of data engineers as architects who design and build the house, while data scientists are the residents who use that house to create value.
How They Collaborate
Sequential Workflow: In most organizations, data engineering work precedes data science work. Data engineers create the infrastructure and pipelines that provide clean, accessible data. Data scientists then use this data for analysis and modeling.
Feedback Loop: Data scientists often request specific data sources, transformations, or features. Data engineers implement these requirements, and the cycle continues as new needs emerge.
Shared Responsibility: Both roles care about data quality, though from different perspectives. Data engineers ensure technical quality (completeness, consistency, timeliness), while data scientists assess analytical quality (relevance, accuracy for modeling purposes).
Common Challenges in Collaboration
- Communication gaps: Data engineers think in terms of systems and pipelines; data scientists think in terms of models and insights. Bridging this gap requires effort from both sides.
- Different priorities: Engineers prioritize reliability and scalability; scientists prioritize flexibility and experimentation speed.
- Tool fragmentation: Different technology stacks can create friction when transitioning work between teams.
Successful data teams establish clear interfaces, shared documentation, and regular communication to overcome these challenges. Organizations that integrate DevOps practices with their data workflows often see better collaboration between engineering and science teams.
Data Engineering Jobs: Market Overview for 2025
The job market for data engineering has exploded in recent years, and 2025 shows no signs of slowing down. As organizations recognize that data science is only as good as the data infrastructure supporting it, demand for data engineers has surged.
Job Market Statistics
- Growth Rate: Data engineering positions are growing approximately 30-35% year over year
- Salary Range:
- Entry level: $85,000 – $120,000
- Mid level: $120,000 – $165,000
- Senior/Principal: $165,000 – $250,000+
- (Varies significantly by location, company size, and industry)
- Entry level: $85,000 – $120,000
- Top Hiring Industries: Technology, finance, healthcare, e commerce, consulting
Common Data Engineering Job Titles
- Data Engineer
- Senior Data Engineer
- Principal Data Engineer
- Analytics Engineer
- Machine Learning Engineer (hybrid role)
- Data Platform Engineer
- Data Infrastructure Engineer
- Big Data Engineer
- Cloud Data Engineer
What Employers Look For
When hiring for data engineering jobs, companies typically seek:
- Strong programming skills, especially in Python and SQL
- Experience with cloud platforms (AWS, GCP, or Azure)
- Knowledge of distributed systems and big data technologies
- Understanding of data modeling and database design
- Familiarity with CI/CD practices and version control
- Problem-solving abilities and attention to detail
- Communication skills to work effectively with cross-functional teams
Career Progression in Data Engineering
The typical career path for data engineers looks like:
Junior Data Engineer Data Engineer Senior Data Engineer Lead/Staff Data Engineer Principal Data Engineer or Engineering Manager
Some data engineers also transition into related roles:
- Data Architect: Focusing on high level system design
- Machine Learning Engineer: Building production ML systems
- DevOps Engineer: Specializing in infrastructure and deployment
- Data Engineering Manager: Leading teams of data engineers
Data Science Jobs: Market Overview for 2025
Data science remains one of the most sought after professions, though the market has matured and become more specialized compared to the early 2010s hype cycle.
Job Market Statistics
- Growth Rate: Data science positions growing approximately 25 28% year-over year
- Salary Range:
- Entry level: $90,000 – $125,000
- Mid level: $125,000 – $175,000
- Senior/Principal: $175,000 – $275,000+
- (Varies by location, industry, and specialization)
- Entry level: $90,000 – $125,000
- Top Hiring Industries: Technology, finance, healthcare, retail, consulting, pharmaceuticals
Common Data Science Job Titles
- Data Scientist
- Senior Data Scientist
- Principal Data Scientist
- Machine Learning Scientist
- Research Scientist
- Applied Scientist
- Data Science Manager
- AI Specialist
- Quantitative Analyst
What Employers Look For
Companies hiring data scientists typically require:
- Strong statistical and mathematical foundation
- Proficiency in Python or R with relevant libraries
- Machine learning experience with real world applications
- Communication skills to explain complex concepts to non technical audiences
- Business acumen to align work with organizational goals
- Experience with data visualization and storytelling
- Domain expertise in relevant industries (increasingly important)
Career Progression in Data Science
The typical career trajectory:
Junior Data Scientist Data Scientist Senior Data Scientist Lead/Staff Data Scientist Principal Data Scientist or Data Science Manager
Alternative paths include:
- Machine Learning Engineer: Focusing on productionizing models
- Data Science Manager/Director: Leading data science teams
- AI Research Scientist: Conducting cutting edge research
- Product Data Scientist: Specializing in product analytics
- Business Intelligence Lead: Focusing on reporting and dashboards
Choosing Between Data Engineering and Data Science
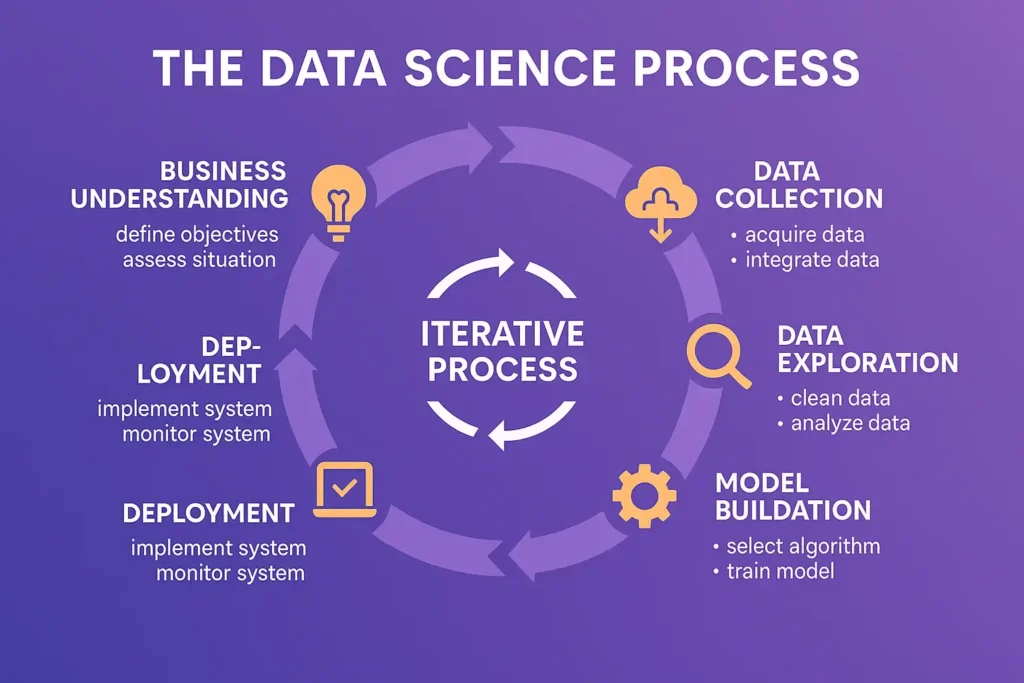
Deciding between these career paths depends on your interests, strengths, and career goals. Here’s a framework to help you choose:
Choose Data Engineering If You:
Enjoy building systems and solving infrastructure challenges
Have a strong software engineering background or interest
Prefer working with code, databases, and distributed systems
Like creating tools and platforms that others use
Find satisfaction in optimizing performance and reliability
Are comfortable with DevOps and cloud environments
Want to work “behind the scenes” enabling data initiatives
Choose Data Science If You:
Love exploring data and uncovering insights
Have a strong background in mathematics and statistics
Enjoy building models and testing hypotheses
Like presenting findings and influencing business decisions
Are curious about machine learning and AI applications
Prefer working directly with business stakeholders
Find satisfaction in solving analytical and predictive problems
Can’t Decide? Consider Hybrid Roles
Some positions blend both disciplines:
- Machine Learning Engineer: Combines data engineering (building ML pipelines) with data science (developing models)
- Analytics Engineer: Focuses on transforming data for analytics (engineering) and creating metrics (science)
- Full-Stack Data Scientist: Handles both infrastructure and analysis in smaller organizations
Educational Paths and Certifications
For Data Engineering
Formal Education:
- Computer Science degree (Bachelor’s or Master’s)
- Software Engineering degree
- Information Systems degree
- Self-taught paths are common and viable
Certifications:
- AWS Certified Data Analytics Specialty
- Google Cloud Professional Data Engineer
- Microsoft Certified: Azure Data Engineer Associate
- Databricks Certified Data Engineer
- Cloudera Certified Professional: Data Engineer
Learning Resources:
- Online platforms: DataCamp, Coursera, Udacity
- Books: “Designing Data Intensive Applications” by Martin Kleppmann
- Practice: Build personal projects using cloud platforms
For Data Science
Formal Education:
- Statistics or Mathematics degree
- Data Science degree (increasingly common)
- PhD in quantitative fields (for research positions)
- Computer Science with ML focus
- Bootcamps (for career changers)
Certifications:
- Google Cloud Professional Machine Learning Engineer
- AWS Certified Machine Learning Specialty
- Microsoft Certified: Azure Data Scientist Associate
- TensorFlow Developer Certificate
- SAS Certified Data Scientist
Learning Resources:
- Online platforms: Kaggle, Fast.ai, Coursera
- Books: “The Elements of Statistical Learning,” “Hands On Machine Learning”
- Practice: Participate in Kaggle competitions, build portfolio projects
The Future of Data Engineering and Data Science
As we progress through 2025 and beyond, both fields continue evolving rapidly. Understanding emerging trends helps professionals stay relevant and organizations plan their hiring strategies.
Emerging Trends in Data Engineering
Real Time Data Processing: Increasing demand for streaming data pipelines and event-driven architectures
DataOps: Applying DevOps principles to data pipelines for faster, more reliable delivery
Data Mesh: Decentralized data architecture treating data as a product
Automated Data Quality: ML powered systems for detecting and fixing data issues
Serverless Data Platforms: Reducing infrastructure management overhead
Privacy Engineering: Building privacy-preserving data systems amid increasing regulations
Emerging Trends in Data Science
AutoML and MLOps: Automating model development and deployment processes
Explainable AI: Making models more interpretable for business users and regulators
Specialized AI Models: Domain-specific models for healthcare, finance, etc.
Generative AI Applications: Leveraging large language models and diffusion models for business use cases
Edge AI: Deploying models on edge devices for real-time inference
Responsible AI: Addressing bias, fairness, and ethical considerations
Both fields are increasingly intersecting with AI-driven innovation across industries, creating new opportunities for professionals who can navigate both engineering and analytical challenges.
Building a Successful Data Team
For organizations, the question isn’t “data engineering vs data science” it’s “how do we effectively combine both?”
Team Structure Best Practices
Small Organizations (< 50 employees):
- Start with versatile individuals who can handle both roles
- Hire data engineers first to build infrastructure
- Add data scientists as data maturity grows
Medium Organizations (50-500 employees):
- Separate data engineering and data science teams
- Maintain 2:1 or 3:1 ratio of engineers to scientists
- Establish clear handoff processes
Large Organizations (500+ employees):
- Specialized teams for different domains
- Platform teams for shared infrastructure
- Embedded data scientists in product teams
- Centralized data engineering team
Essential Team Dynamics
Successful data organizations foster:
- Shared Goals: Align both teams around business outcomes, not just technical metrics
- Cross-Training: Engineers learn basic statistics; scientists understand data pipelines
- Regular Communication: Weekly syncs, shared documentation, collaborative tools
- Respect for Expertise: Recognize the distinct value each role provides
- Continuous Learning: Encourage attendance at conferences and ongoing education
For more insights on building effective data teams, explore our blog for additional resources.
Practical Advice for Career Changers
Transitioning into data engineering or data science from another field is increasingly common. Here’s how to make the switch:
Breaking Into Data Engineering
- Build Programming Skills: Focus on Python and SQL first
- Learn Cloud Platforms: Get hands-on with AWS, GCP, or Azure free tiers
- Create Portfolio Projects: Build ETL pipelines, set up databases, automate workflows
- Contribute to Open Source: Participate in data engineering projects on GitHub
- Network: Attend meetups, join online communities, connect with practitioners
- Start Adjacent: Consider roles like backend engineer, database administrator, or DevOps engineer as stepping stones
Breaking Into Data Science
- Strengthen Math Foundations: Review statistics, linear algebra, and calculus
- Master Python: Learn pandas, NumPy, scikit-learn, and visualization libraries
- Complete Kaggle Competitions: Build practical ML skills and create portfolio pieces
- Develop Domain Expertise: Specialize in an industry where you have background knowledge
- Build a Portfolio: Create projects demonstrating end to end data science workflows
- Start Adjacent: Consider roles like data analyst or business intelligence developer as entry points
Common Misconceptions
Let’s address some widespread myths about data engineering and data science:
Myth 1: “Data scientists are more valuable than data engineers”
Reality: Both roles are equally critical. Without robust data engineering, data science initiatives fail.
Myth 2: “Data engineering is just writing SQL queries”
Reality: Modern data engineering involves complex distributed systems, cloud architecture, and software engineering principles.
Myth 3: “You need a PhD to be a data scientist”
Reality: While PhDs are common in research-focused roles, many successful data scientists have Bachelor’s or Master’s degrees, or are self-taught.
Myth 4: “Data engineers don’t need to understand statistics”
Reality: Understanding basic statistics helps data engineers make better design decisions and communicate with data scientists.
Myth 5: “Data science is all about machine learning”
Reality: Much of data science involves data cleaning, exploratory analysis, and communicating findings not just building ML models.
Salary Expectations and Compensation
Understanding compensation helps professionals negotiate effectively and organizations budget appropriately. Here’s a detailed breakdown of salary expectations in 2025:
Data Engineering Salaries
Entry-Level (0-2 years):
- Base: $85,000 – $120,000
- Total compensation: $95,000 – $140,000
- Top markets (SF, NYC, Seattle): +20-30%
Mid-Level (3-5 years):
- Base: $120,000 – $165,000
- Total compensation: $140,000 – $200,000
- Senior engineers with specialized skills command premium rates
Senior/Principal (6+ years):
- Base: $165,000 – $250,000+
- Total compensation: $200,000 $400,000+
- Staff/Principal engineers at FAANG: $400,000 – $600,000+
Data Science Salaries
Entry-Level (0-2 years):
- Base: $90,000 – $125,000
- Total compensation: $100,000 $145,000
- PhD candidates may start higher
Mid-Level (3-5 years):
- Base: $125,000 – $175,000
- Total compensation: $145,000 $220,000
- Specialization in high-demand areas (NLP, computer vision) adds premium
Senior/Principal (6+ years):
- Base: $175,000 – $275,000+
- Total compensation: $220,000 – $450,000+
- Research scientists at top labs: $500,000+
Factors Affecting Compensation
Location: San Francisco, New York, and Seattle offer highest salaries
Company Size: Large tech companies typically pay more than startups
Industry: Finance and tech generally pay more than non profits or education
Specialization: Niche skills (real-time ML, distributed systems) command premiums
Education: Advanced degrees can increase starting salaries 10 20%
Negotiation: Strong negotiators can increase offers by 15 25%
Real-World Success Stories
Understanding how professionals navigate these careers provides valuable perspective:
From Software Engineer to Data Engineer
Sarah’s Journey: Sarah spent three years as a backend engineer at a fintech company. When her team struggled with data pipeline reliability, she volunteered to rebuild their ETL processes. This sparked her interest in data engineering. She took online courses in Apache Spark and AWS, then transitioned internally to a data engineering role. Two years later, she’s a senior data engineer earning $175,000 and leads a team of five.
Key Lesson: Leverage adjacent experience and volunteer for data-related projects in your current role.
From Academia to Data Science
Dr. Chen’s Transition: After completing a PhD in computational biology, Dr. Chen joined a healthcare startup as a data scientist. His research background in statistical modeling translated well, though he had to learn production coding practices. He focused on building explainable models for clinical decision support. Now a principal data scientist, he earns $260,000 and publishes papers combining industry and academic work.
Key Lesson: PhD holders should emphasize practical applications and learn software engineering best practices.
Career Switcher to Data Engineering
Marcus’s Path: Marcus worked in marketing for five years before deciding to change careers. He completed a data engineering bootcamp while working full-time, built portfolio projects using cloud platforms, and contributed to open-source data tools. After six months of job searching, he landed a junior data engineer position at $95,000. Three years later, he’s a mid-level engineer at $145,000.
Key Lesson: Career changers need patience, strong portfolios, and willingness to start at entry-level positions.
Tools and Technologies Comparison
Data Engineering Stack
Data Ingestion:
- Apache Kafka (streaming)
- Apache NiFi (batch/streaming)
- Fivetran, Airbyte (managed connectors)
Data Processing:
- Apache Spark (distributed processing)
- Apache Flink (stream processing)
- dbt (analytics engineering)
Data Storage:
- Snowflake, BigQuery, Redshift (warehouses)
- S3, GCS, Azure Blob (object storage)
- PostgreSQL, MySQL (relational databases)
- MongoDB, Cassandra (NoSQL)
Orchestration:
- Apache Airflow
- Prefect
- Dagster
Cloud Platforms:
- AWS (Glue, EMR, Redshift, S3)
- Google Cloud (Dataflow, BigQuery, Cloud Storage)
- Azure (Data Factory, Synapse, Databricks)
Data Science Stack
Programming & Analysis:
- Python (pandas, NumPy, SciPy)
- R (tidyverse, ggplot2)
- Jupyter Notebooks
Machine Learning:
- scikit-learn (traditional ML)
- TensorFlow, PyTorch (deep learning)
- XGBoost, LightGBM (gradient boosting)
- Hugging Face (NLP models)
Visualization:
- Matplotlib, Seaborn (Python)
- Plotly, Bokeh (interactive)
- Tableau, Power BI (BI tools)
Experiment Tracking:
- MLflow
- Weights & Biases
- Neptune.ai
Model Deployment:
- Docker, Kubernetes
- AWS SageMaker
- Google Vertex AI
- Azure ML
Industry Specific Considerations
Different industries have unique requirements for data engineering and data science roles:
Technology Companies
Data Engineering: Focus on scalability, real time processing, and handling massive user data
Data Science: Emphasis on recommendation systems, personalization, and product analytics
Example: Building real time fraud detection systems or content recommendation engines
Financial Services
Data Engineering: Strict compliance requirements, low-latency systems, data security
Data Science: Risk modeling, algorithmic trading, fraud detection, credit scoring
Example: High frequency trading infrastructure or loan default prediction models
Healthcare
Data Engineering: HIPAA compliance, integration with legacy systems, data privacy
Data Science: Predictive diagnostics, clinical decision support, drug discovery
Example: Patient readmission prediction or medical imaging analysis
E-commerce
Data Engineering: Real-time inventory systems, clickstream processing, integration of multiple data sources
Data Science: Customer segmentation, dynamic pricing, demand forecasting
Example: Personalized product recommendations or inventory optimization
Manufacturing
Data Engineering: IoT data ingestion, sensor data processing, operational data integration
Data Science: Predictive maintenance, quality control, supply chain optimization
Example: Equipment failure prediction or production line optimization
Conclusion
The distinction between data engineering and data science represents more than just different job titles; it reflects two complementary approaches to extracting value from data. Data engineers build the highways and infrastructure that enable data to flow efficiently through organizations. Data scientists are the explorers who travel those highways to discover insights and create predictive capabilities.
Both roles are essential in 2025’s data-driven economy. Organizations that understand these distinctions and build balanced teams will outperform competitors who neglect either discipline. For professionals, choosing between data engineering and data science depends on your interests, strengths, and career aspirations but both paths offer rewarding careers with strong growth prospects.


