In a world where businesses generate 2.5 quintillion bytes of data every single day, someone needs to build the infrastructure that makes sense of it all. That someone is a big data engineer, the architect behind the data pipelines that power everything from Netflix recommendations to fraud detection systems at major banks. As artificial intelligence and machine learning continue to reshape industries, the demand for skilled data engineering professionals has skyrocketed, making this one of the most lucrative and future proof careers in technology.
Key Takeaways
- Big data engineers design, build, and maintain the infrastructure that allows organizations to collect, store, and analyze massive datasets efficiently
- Average salaries range from $110,000 to $180,000+ annually in the United States, with senior positions commanding even higher compensation
- Essential skills include programming (Python, Java, Scala), database management (SQL/NoSQL), cloud platforms (AWS, Azure, GCP), and distributed computing frameworks (Hadoop, Spark)
- Career growth is exceptional, with opportunities to advance into senior engineering, architecture, or leadership roles as data becomes increasingly central to business strategy
- The field intersects with AI and machine learning, requiring engineers to understand how their infrastructure supports advanced analytics and intelligent systems
Understanding the Big Data Engineer Role
What Does a Big Data Engineer Do?
A big data engineer is a specialized software engineer who focuses on designing, constructing, and maintaining systems that can process and analyze enormous volumes of data. Unlike traditional software engineers who might build user facing applications, big data engineers work behind the scenes to create the data infrastructure that powers modern organizations.
Their primary responsibilities include:
- Building data pipelines that extract data from various sources, transform it into usable formats, and load it into storage systems (ETL/ELT processes)
- Designing and implementing databases and data warehouses optimized for large scale analytics
- Developing data processing frameworks using distributed computing technologies
- Ensuring data quality, security, and compliance with industry regulations
- Collaborating with data scientists and analysts to make data accessible and usable for business insights
- Optimizing system performance to handle increasing data volumes efficiently
As big data continues to evolve, these professionals serve as the critical link between raw information and actionable business intelligence.
Big Data Engineer vs. Data Scientist vs. Data Analyst
Many people confuse these three roles, but they have distinct focuses and responsibilities:
| Role | Primary Focus | Key Activities | Typical Background |
|---|---|---|---|
| Big Data Engineer | Infrastructure & Architecture | Building pipelines, managing databases, optimizing systems | Software Engineering, Computer Science |
| Data Scientist | Analysis & Modeling | Creating predictive models, statistical analysis, machine learning | Statistics, Mathematics, Data Science |
| Data Analyst | Reporting & Insights | Creating dashboards, generating reports, business intelligence | Business Analytics, Statistics |
Think of it this way: Data engineers build the kitchen and ensure all the appliances work; data scientists are the chefs who create new recipes; data analysts are the food critics who interpret what the dishes mean for customers.
The Evolution of Data Engineering
The field of data engineering has transformed dramatically over the past two decades:
Early 2000s: Traditional database administrators managed relatively small datasets on premise servers using relational databases.
2010s: The explosion of web data led to the development of Hadoop and distributed computing frameworks, creating the need for specialized big data engineers.
2020s: Cloud computing, real time streaming data, and the integration with artificial intelligence applications have made data engineering more complex and critical than ever.
Today’s big data engineers must navigate an ecosystem that includes batch processing, stream processing, data lakes, data warehouses, and increasingly sophisticated machine learning pipelines.
Essential Skills for Big Data Engineers
Programming Languages
Python stands as the most popular language in data engineering due to its versatility, extensive libraries, and readability. Engineers use Python for:
- Writing ETL scripts
- Data manipulation with pandas and NumPy
- Automation and orchestration
- Integration with machine learning frameworks
Java and Scala remain essential for working with Apache Spark and other JVM based big data frameworks. Their performance advantages make them ideal for processing massive datasets.
SQL is non negotiable regardless of how advanced the technology stack becomes, the ability to query, manipulate, and optimize relational databases remains fundamental.
Big Data Technologies and Frameworks
Modern big data engineers must be proficient in several key technologies:
Apache Hadoop Ecosystem:
- HDFS (Hadoop Distributed File System) for distributed storage
- MapReduce for distributed processing
- YARN for resource management
- Hive for SQL like queries on big data
Apache Spark:
- In memory processing for faster analytics
- Support for batch and stream processing
- Libraries for machine learning (MLlib) and graph processing (GraphX)
- Integration with various data sources
Stream Processing:
- Apache Kafka for real time data streaming
- Apache Flink for stateful stream processing
- AWS Kinesis for cloud-based streaming
NoSQL Databases:
- MongoDB for document storage
- Cassandra for distributed wide column storage
- Redis for caching and real time applications
- HBase for random, real time read write access
Cloud Platforms and Services
Cloud computing has revolutionized data engineering, making scalable infrastructure accessible to organizations of all sizes. The major platforms include:
Amazon Web Services (AWS):
- S3 for object storage
- Redshift for data warehousing
- EMR for managed Hadoop/Spark clusters
- Glue for ETL services
- Athena for serverless queries
Microsoft Azure:
- Azure Data Lake Storage
- Azure Synapse Analytics
- Azure Databricks
- Azure Data Factory
Google Cloud Platform (GCP):
- BigQuery for serverless data warehousing
- Cloud Dataflow for stream and batch processing
- Cloud Dataproc for managed Spark/Hadoop
- Cloud Pub Sub for messaging
Understanding DevOps practices in cloud environments is increasingly important as data engineering teams adopt infrastructure as code and continuous integration continuous deployment (CI/CD) methodologies.
Data Modeling and Architecture
Conceptual understanding of data architecture patterns is crucial:
- Data Lakes: Centralized repositories storing structured and unstructured data at scale
- Data Warehouses: Optimized for analytical queries and business intelligence
- Lambda Architecture: Combining batch and real time processing
- Kappa Architecture: Stream first approach to data processing
- Medallion Architecture: Bronze, silver, and gold data layers for progressive refinement
Engineers must design schemas that balance normalization (reducing redundancy) with denormalization (optimizing for query performance) based on specific use cases.
Soft Skills and Business Acumen
Technical expertise alone isn’t sufficient. Successful big data engineers also develop:
- Communication skills to explain complex technical concepts to non technical stakeholders
- Collaboration abilities to work effectively with cross functional teams
- Problem solving mindset to troubleshoot issues in distributed systems
- Business understanding to align technical solutions with organizational goals
- Adaptability to keep pace with rapidly evolving technologies
Educational Pathways and Certifications
Formal Education
While not always mandatory, most big data engineers hold at least a bachelor’s degree in:
- Computer Science
- Software Engineering
- Information Technology
- Data Science
- Mathematics or Statistics
Master’s degrees in Data Science, Computer Science, or related fields can accelerate career advancement and provide deeper theoretical knowledge, particularly in machine learning and advanced algorithms.
Self Learning and Online Resources
The democratization of education has made it possible to break into data engineering through self study:
Online Learning Platforms:
- Coursera (offers specializations from top universities)
- Udacity (Nanodegree programs with hands on projects)
- DataCamp (interactive coding challenges)
- Pluralsight (comprehensive technology courses)
- LinkedIn Learning (professional development)
Free Resources:
- Apache project documentation
- Cloud provider tutorials and free tiers
- YouTube channels dedicated to data engineering
- GitHub repositories with sample projects
- Tech blogs and industry insights
Professional Certifications
Certifications validate expertise and can differentiate candidates in competitive job markets:
Cloud Certifications:
- AWS Certified Data Analytics Specialty
- Google Cloud Professional Data Engineer
- Microsoft Certified: Azure Data Engineer Associate
Technology-Specific:
- Cloudera Certified Professional (CCP) Data Engineer
- Databricks Certified Data Engineer Professional
- MongoDB Certified Developer
General:
- Certified Analytics Professional (CAP)
- TOGAF for enterprise architecture
Certifications are particularly valuable for career changers or those without traditional computer science degrees.
Career Path and Progression
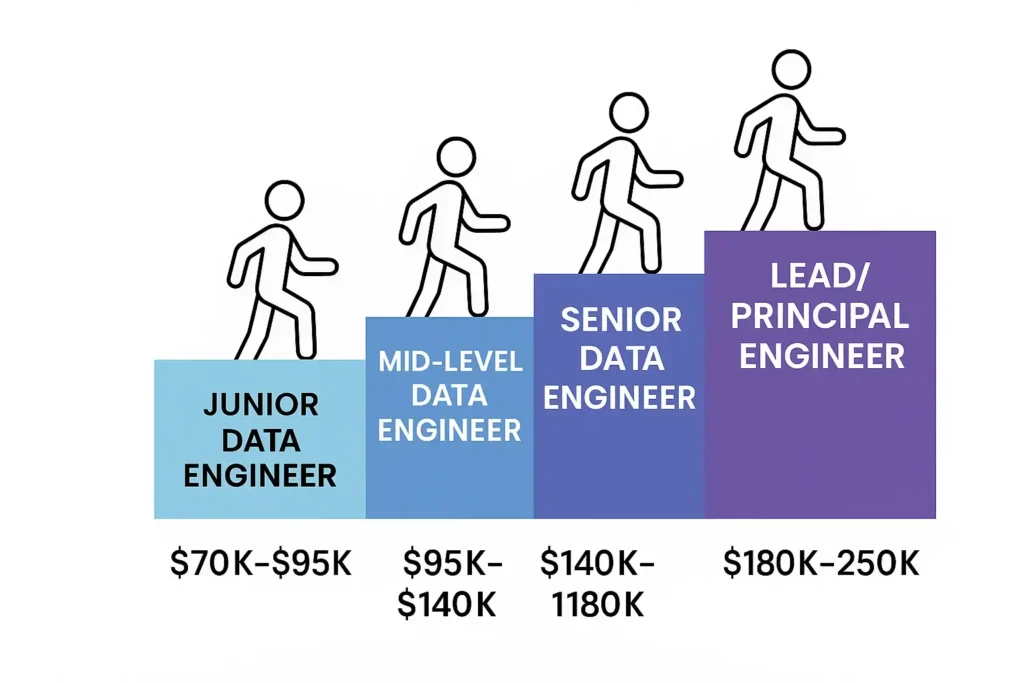
Entry Level Positions
Junior Data Engineer or Associate Data Engineer roles typically require:
- 0-2 years of experience
- Strong foundation in programming and SQL
- Basic understanding of data pipelines
- Willingness to learn and adapt
Salary range: $70,000 – $95,000
Entry level engineers often start by:
- Maintaining existing data pipelines
- Writing basic ETL scripts
- Assisting with data quality checks
- Learning the organization’s data infrastructure
Mid Level Positions
Data Engineer roles expect:
- 2-5 years of experience
- Proficiency in multiple big data technologies
- Ability to design and implement complete data solutions
- Experience with cloud platforms
Salary range: $95,000 – $140,000
Mid-level engineers take on:
- Designing new data pipelines
- Optimizing existing infrastructure
- Mentoring junior team members
- Collaborating directly with data scientists
Senior Level Positions
Senior Data Engineer or Lead Data Engineer positions require:
- 5+ years of experience
- Deep expertise in distributed systems
- Architectural decision-making abilities
- Leadership and mentoring skills
Salary range: $140,000 – $180,000+
Senior engineers focus on:
- Architecting enterprise scale data platforms
- Setting technical standards and best practices
- Leading complex projects
- Strategic planning for data infrastructure
Advanced Career Opportunities
Beyond senior engineering roles, several advancement paths exist:
Data Architect: Designing organization wide data strategies and frameworks ($150,000 – $200,000+)
Engineering Manager: Leading teams of data engineers with both technical and people management responsibilities ($160,000 – $220,000+)
Principal Engineer: Serving as a technical authority across multiple teams and projects ($180,000 – $250,000+)
VP of Data Engineering: Executive leadership overseeing all data engineering operations ($200,000 – $350,000+)
The integration of DevOps best practices into data engineering workflows has also created hybrid roles like DataOps Engineer and ML Engineer, expanding career possibilities.
The Intersection of Big Data Engineering and Artificial Intelligence
Supporting Machine Learning Infrastructure
Big data engineers play a crucial role in the AI transformation of modern businesses. They build the foundation that enables machine learning models to function:
Feature Stores: Creating centralized repositories of features (input variables) that data scientists can use for model training and inference.
Model Training Pipelines: Developing automated workflows that retrain models as new data becomes available.
Inference Infrastructure: Building low-latency systems that serve predictions from trained models to applications in real-time.
Data Versioning: Implementing systems to track data lineage and ensure reproducibility of machine learning experiments.
Real Time AI Applications
The demand for real time AI capabilities has pushed data engineering to new levels of sophistication:
- Streaming analytics for fraud detection in financial transactions
- Recommendation engines that update based on user behavior in milliseconds
- Predictive maintenance systems analyzing sensor data from industrial equipment
- Personalization platforms delivering customized content at scale
Engineers must design systems with minimal latency while maintaining high throughput and fault tolerance a challenging balance that requires deep technical expertise.
MLOps and the Evolution of Data Engineering
The emergence of MLOps (Machine Learning Operations) represents the convergence of data engineering, DevOps, and machine learning. Big data engineers increasingly need to understand:
- Model deployment strategies
- A/B testing frameworks for models
- Monitoring and alerting for model performance degradation
- Automated retraining pipelines
- Model governance and compliance
This evolution has made generative AI applications possible at enterprise scale, as engineers build the infrastructure to handle the massive computational and data requirements of large language models and other advanced AI systems.
Industry Applications and Use Cases
E Commerce and Retail
Big data engineers in retail build systems that:
- Process millions of transactions daily for real time inventory management
- Power recommendation engines that drive 30-40% of revenue for major platforms
- Analyze customer behavior across multiple channels for personalized marketing
- Optimize pricing dynamically based on demand, competition, and inventory levels
Example: A major online retailer’s data engineering team processes over 15 petabytes of data daily, supporting everything from search functionality to fraud detection.
Financial Services
In banking and finance, data engineers create:
- Fraud detection systems analyzing transactions in real time across global networks
- Risk modeling platforms processing market data for trading algorithms
- Regulatory compliance systems ensuring data governance and audit trails
- Customer analytics for personalized financial product recommendations
The financial sector offers some of the highest salaries for data engineers due to the critical nature of the work and regulatory requirements.
Healthcare and Life Sciences
Healthcare data engineering involves:
- Integrating data from electronic health records, medical devices, and research databases
- Building platforms for genomic data analysis requiring massive computational power
- Creating real time monitoring systems for patient care
- Developing data lakes that support medical research while maintaining HIPAA compliance
Challenge: Healthcare data is particularly complex, involving structured, semi structured, and unstructured data (images, clinical notes, sensor readings) that must be integrated while maintaining strict privacy controls.
Technology and Social Media
Tech companies pioneered many big data technologies and continue to push boundaries:
- Social media platforms processing billions of posts, likes, and interactions daily
- Streaming services delivering personalized content to hundreds of millions of users
- Cloud providers building infrastructure that other organizations use for their data needs
- Search engines indexing and serving results from the entire internet in milliseconds
These organizations often develop proprietary technologies that later become open source standards used across industries.
Challenges and Opportunities in Big Data Engineering
Current Challenges
Data Quality and Governance: As data sources proliferate, ensuring consistency, accuracy, and compliance becomes increasingly difficult. Engineers must implement robust validation, cleaning, and monitoring processes.
Scalability: Systems that work well with gigabytes of data often fail when scaled to petabytes. Designing for future growth while managing current costs requires careful architectural planning.
Technology Fragmentation: The explosion of tools and platforms creates decision paralysis. Choosing the right technology stack for specific use cases requires both technical knowledge and business understanding.
Security and Privacy: With regulations like GDPR, CCPA, and industry specific requirements, engineers must build security and privacy into every layer of the data infrastructure.
Talent Shortage: The demand for skilled big data engineers far exceeds supply, creating competitive hiring environments and making it difficult for organizations to build strong teams.
Emerging Opportunities
Serverless Data Processing: Cloud providers increasingly offer serverless options that eliminate infrastructure management, allowing engineers to focus on logic rather than operations.
Data Mesh Architecture: Decentralized approaches to data ownership are gaining traction, creating new patterns for organizing data engineering teams and systems.
Real-Time Everything: The shift from batch processing to stream processing continues, opening opportunities for engineers skilled in real time systems.
Edge Computing: Processing data closer to where it’s generated (IoT devices, mobile phones) creates new architectural challenges and opportunities.
Sustainability: As data centers consume increasing amounts of energy, engineers who can optimize for both performance and environmental impact will be increasingly valuable.
The integration of DevOps with cloud services continues to create new methodologies and tools that data engineers must master.
Building Your Big Data Engineering Career
Creating a Strong Portfolio
Practical experience matters more than theoretical knowledge in data engineering. Build a portfolio that demonstrates:
Personal Projects:
- Create an end to end data pipeline using real world datasets (publicly available from Kaggle, government sources, or APIs)
- Build a data warehouse and create dashboards visualizing insights
- Implement a real time streaming application using Kafka and Spark
- Contribute to open source data engineering projects
Documentation: Write about your projects, explaining architectural decisions, challenges faced, and solutions implemented. This demonstrates both technical skills and communication abilities.
GitHub Repository: Maintain clean, well-documented code that potential employers can review. Include README files explaining how to run your projects.
Networking and Community Engagement
Professional Communities:
- Join data engineering Slack channels and Discord servers
- Participate in local meetups and conferences
- Engage on LinkedIn with thought leaders in the field
- Contribute to Stack Overflow and Reddit communities
Conferences and Events:
- Strata Data Conference
- DataEngConf
- Spark Summit
- Cloud specific events (AWS re:Invent, Google Cloud Next, Microsoft Build)
Online Presence: Share knowledge through blog posts, tutorials, or YouTube videos. Teaching others solidifies your own understanding and builds your professional reputation.
Job Search Strategies
Tailor Your Resume:
- Emphasize relevant technologies from job descriptions
- Quantify achievements (e.g., “Reduced data processing time by 40%”)
- Highlight both technical skills and business impact
- Include certifications and continuous learning efforts
Interview Preparation:
- Practice coding challenges on LeetCode and HackerRank
- Study system design for distributed systems
- Prepare to explain your past projects in detail
- Research the company’s data infrastructure and challenges
Evaluate Opportunities:
- Consider the tech stack and learning opportunities
- Assess the data maturity of the organization
- Evaluate the team structure and mentorship possibilities
- Look beyond salary to total compensation and growth potential
The Future of Big Data Engineering
Trends Shaping the Field
Automation and AI Assisted Engineering: Tools that automatically generate data pipelines, optimize queries, and detect anomalies will augment (not replace) human engineers, allowing them to focus on higher level architectural decisions.
Data Fabric and Data Mesh: New architectural paradigms that treat data as a product and distribute ownership across domain teams will reshape how organizations structure their data engineering efforts.
Increased Regulation: Privacy laws and AI governance frameworks will require engineers to build compliance into systems from the ground up, creating demand for expertise in data governance.
Quantum Computing: While still emerging, quantum computing may eventually transform how certain types of data processing are performed, requiring engineers to develop new skills.
Sustainability Focus: Organizations will increasingly prioritize green data engineering optimizing systems not just for performance and cost, but also for environmental impact.
Skills That Will Remain Valuable
Despite rapid technological change, certain core competencies will remain essential:
- Fundamental computer science concepts (algorithms, data structures, distributed systems)
- Problem solving abilities that transcend specific tools
- Understanding of data modeling and architectural patterns
- Communication and collaboration skills for working with diverse teams
- Continuous learning mindset to adapt to new technologies
The field continues to evolve alongside innovations in generative AI, creating exciting opportunities for engineers who stay current with emerging technologies while maintaining strong fundamentals.
Conclusion: Your Path to Becoming a Big Data Engineer
The role of a big data engineer represents one of the most dynamic and rewarding careers in technology today. As organizations across every industry recognize that data is their most valuable asset, the professionals who can build, maintain, and optimize data infrastructure will remain in high demand.


