The world of data engineering is experiencing its most profound transformation since the advent of cloud computing. As artificial intelligence reshapes industries at an unprecedented pace, data engineers find themselves at the epicenter of this revolution, wielding tools and techniques that would have seemed like science fiction just a decade ago. The traditional role of building data pipelines and maintaining warehouses has evolved into something far more strategic architecting intelligent systems that can learn, adapt, and deliver insights at machine speed.
In 2025, organizations are drowning in data yet starving for actionable intelligence. The gap between raw data collection and AI powered decision making has never been more critical to bridge. This is where modern data engineering steps in, armed with new paradigms, automated workflows, and AI-native architectures that are fundamentally changing how businesses harness the power of information.
Key Takeaways
- AI driven automation is transforming data engineering workflows, reducing manual pipeline maintenance by up to 70% while improving data quality and reliability
- Modern data engineering roles now require expertise in machine learning operations (MLOps), real time streaming, and AI model deployment alongside traditional ETL skills
- The convergence of big data and AI has created unprecedented demand for data engineering jobs, with salaries increasing 25-30% year over year in 2025
- Data mesh and lakehouse architectures are replacing traditional data warehouses, enabling faster AI model training and more flexible analytics
- Ethical data engineering practices have become essential, with responsible AI requiring robust data governance, lineage tracking, and bias detection
The Evolution of Data Engineering: From ETL to AI First Architectures
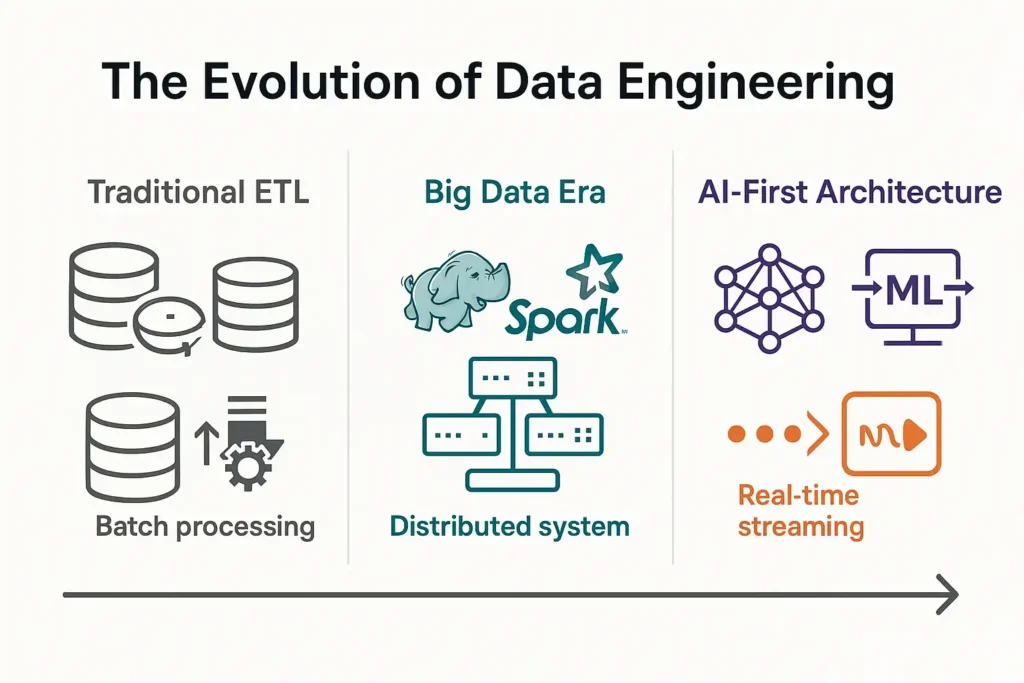
Traditional Data Engineering: The Foundation
Data engineering has historically focused on the “three E’s”: Extract, Transform, and Load (ETL). Data engineers built pipelines that moved information from source systems into centralized data warehouses, where analysts could query and generate reports. This batch processing model worked well for business intelligence and historical analysis.
The traditional data stack included:
- Relational databases for structured data storage
- ETL tools like Informatica or Talend for data movement
- Data warehouses such as Oracle or Teradata for analytics
- Batch processing frameworks for scheduled transformations
- BI tools for reporting and visualization
However, this architecture struggled with the volume, velocity, and variety demands of modern big data applications.
The Big Data Revolution
The emergence of big data technologies around 2010 marked the first major shift. Hadoop, Spark, and NoSQL databases enabled organizations to process petabytes of unstructured data. Data engineers evolved from database administrators into distributed systems specialists who could:
- Design fault tolerant data pipelines across clusters
- Optimize MapReduce jobs for massive datasets
- Implement real time streaming with Kafka and Flink
- Build data lakes that stored raw, unprocessed information
- Handle semi structured and unstructured data formats
This era established data engineering as a distinct discipline, separate from traditional database management and software engineering.
The AI Inflection Point
The current transformation, driven by artificial intelligence and machine learning, represents an even more fundamental shift. Artificial intelligence doesn’t just change what data engineers build it changes how they build it.
Modern AI first data engineering encompasses:
- Feature stores that serve ML models with low latency data access
- Automated data quality monitoring using anomaly detection algorithms
- Self optimizing pipelines that adjust based on usage patterns
- Embedded ML models within data transformation logic
- Real time inference infrastructure supporting production AI applications
- Metadata driven architectures enabling automated data discovery
How Artificial Intelligence is Transforming Data Engineering Workflows
1. Intelligent Pipeline Automation
AI is automating tasks that previously consumed 60-70% of a data engineer’s time. Machine learning algorithms now:
- Auto detect schema changes and adapt pipelines accordingly
- Predict pipeline failures before they occur, enabling proactive maintenance
- Optimize resource allocation across distributed computing clusters
- Generate data transformation code from natural language descriptions
- Automatically tune performance parameters based on workload patterns
Example in Practice: DataOps platforms like Monte Carlo and Datafold use ML to monitor data pipelines continuously, detecting anomalies in data volume, freshness, and distribution that might indicate upstream issues.
2. AI Powered Data Quality and Governance
Data quality has always been critical, but AI applications are far less forgiving of dirty data than traditional analytics. Modern data engineering incorporates:
| Traditional Approach | AI Enhanced Approach |
|---|---|
| Rule based validation checks | ML powered anomaly detection |
| Manual data profiling | Automated pattern recognition |
| Static data quality rules | Adaptive quality thresholds |
| Reactive error handling | Predictive quality monitoring |
| Manual lineage documentation | Automated lineage tracking with graph ML |
These AI driven quality systems can identify subtle data drift, detect biases in training datasets, and ensure compliance with regulatory requirements all automatically.
3. Natural Language Interfaces for Data Access
Generative AI is democratizing data access through natural language interfaces. Data engineers are now building systems where business users can:
- Query databases using conversational language
- Generate SQL from plain English descriptions
- Receive automated insights and summaries
- Create visualizations through voice commands
This shift doesn’t eliminate the need for data engineers instead, it elevates their role to architecting intelligent data platforms that can serve both human analysts and AI agents.
4. Real Time Feature Engineering at Scale
Machine learning models require carefully crafted features derived from raw data. In the AI era, data engineers build feature platforms that:
- Compute features in real time as events occur
- Maintain consistency between training and inference environments
- Version and track feature definitions across models
- Serve millions of feature requests per second with sub 10ms latency
- Enable feature reuse across multiple ML projects
Companies like Uber, Netflix, and Airbnb have pioneered feature stores (Michelangelo, Metaflow, Zipline) that have become essential infrastructure for AI at scale.
The Modern Data Engineering Technology Stack in 2025
Cloud Native Foundations
The shift to cloud computing has accelerated dramatically, with over 85% of enterprise data workloads now running on cloud platforms. Modern data engineering leverages:
Compute & Storage:
- Serverless data processing (AWS Lambda, Google Cloud Functions, Azure Functions)
- Object storage (S3, GCS, Azure Blob) as the foundation for data lakes
- Containerized workflows using Kubernetes for portability
- GPU clusters for ML model training and large-scale transformations
Data Platforms:
- Snowflake, Databricks, BigQuery for unified analytics and ML
- Lakehouse architectures combining data lake flexibility with warehouse performance
- Apache Iceberg, Delta Lake, Apache Hudi for ACID transactions on data lakes
- Streaming platforms like Confluent Cloud (managed Kafka) for real time data
AI Native Data Tools
Purpose built tools for AI workflows have emerged as essential components:
MLOps & Model Deployment:
- MLflow, Kubeflow, Weights & Biases for experiment tracking
- Seldon, BentoML, Ray Serve for model serving
- Feature stores (Feast, Tecton) for ML feature management
- Model monitoring (Arize, Fiddler) for production AI observability
Data Orchestration:
- Airflow, Prefect, Dagster with ML aware scheduling
- dbt (data build tool) for analytics engineering and transformation
- Mage.ai for AI powered pipeline development
- Temporal for durable workflow execution
Data Quality & Observability:
- Great Expectations for data validation
- Monte Carlo, Datafold for data reliability
- OpenMetadata, DataHub for metadata management
- Amundsen for data discovery
Programming Languages and Frameworks
The language landscape has consolidated around tools optimized for both data processing and AI:
Python remains dominant (used by 75%+ of data engineers) due to:
- Rich ecosystem of data libraries (Pandas, Polars, Dask)
- Seamless ML integration (scikit learn, TensorFlow, PyTorch)
- Strong support for distributed computing (PySpark, Ray)
SQL has evolved with new capabilities:
- Window functions and advanced analytics
- ML model training directly in SQL (BigQuery ML, Snowflake Snowpark)
- Integration with Python through SQL mesh architectures
Rust and Go are gaining traction for:
- High performance data processing engines
- Building custom data tools and CLIs
- Infrastructure components requiring low latency
The Changing Landscape of Data Engineering Jobs
Explosive Growth and Demand
The job market for data engineers has never been stronger. According to 2025 industry reports:
- Data engineering jobs grew by 45% year-over-year, outpacing software engineering (18%) and data science (22%)
- Average salaries range from $120,000 for entry level positions to $250,000+ for senior roles at major tech companies
- Remote opportunities have expanded globally, with 65% of data engineering positions offering flexible work arrangements
- Demand significantly exceeds supply, with an average of 4.2 open positions for every qualified candidate
Evolving Role Definitions
The title “data engineer” now encompasses several specialized tracks:
1. Analytics Engineer
- Focuses on transforming data for business intelligence
- Expert in SQL, dbt, and data modeling
- Bridges gap between data engineering and analytics
- Typical tools: dbt, SQL, Looker, Tableau
2. ML Engineer / MLOps Engineer
- Deploys and maintains machine learning models in production
- Builds infrastructure for model training and serving
- Manages feature stores and model registries
- Typical tools: Kubernetes, MLflow, TensorFlow Serving, PyTorch
3. Data Platform Engineer
- Designs and maintains core data infrastructure
- Builds self service data platforms for organizations
- Focuses on scalability, reliability, and developer experience
- Typical tools: Airflow, Kafka, Spark, cloud platforms
4. Streaming Data Engineer
- Specializes in real time data processing
- Builds event driven architectures
- Optimizes for low latency data delivery
- Typical tools: Kafka, Flink, Pulsar, Kinesis
5. AI Infrastructure Engineer
- Builds platforms specifically for AI/ML workloads
- Optimizes GPU utilization and distributed training
- Implements MLOps best practices
- Typical tools: Ray, Kubeflow, Vertex AI, SageMaker
Essential Skills for 2025 and Beyond
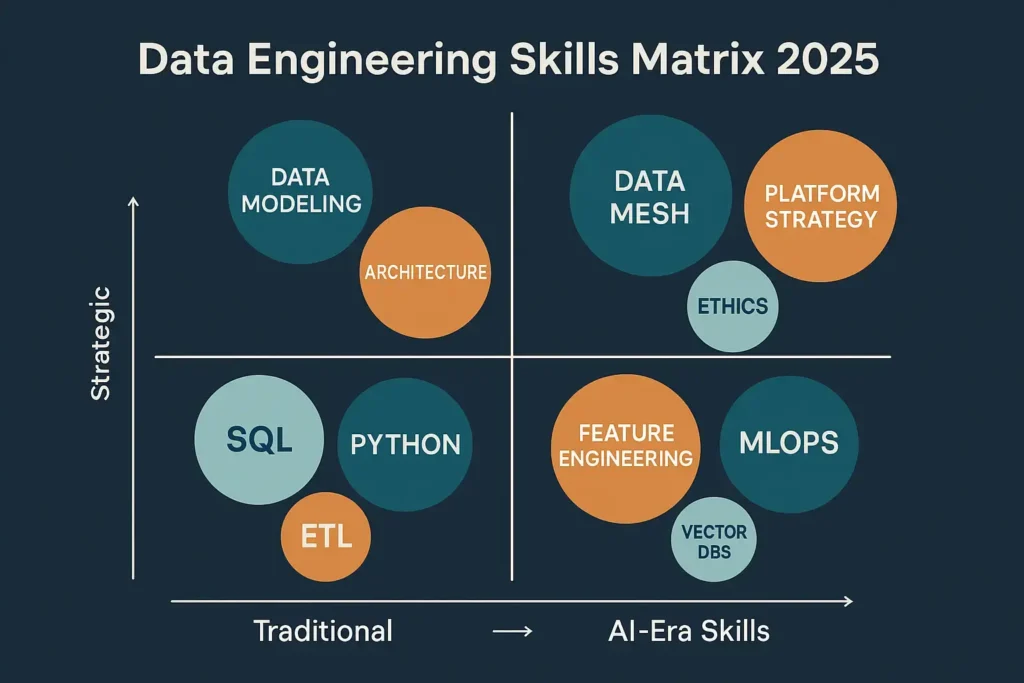
To thrive in modern data engineering roles, professionals need a combination of traditional and emerging skills.
Core Technical Skills:
- Python programming with strong software engineering fundamentals
- SQL mastery including query optimization and performance tuning
- Cloud platforms (AWS, GCP, or Azure) with infrastructure-as-code
- Distributed computing concepts (Spark, Dask, or Ray)
- Data modeling for both analytical and operational use cases
- Version control and CI/CD practices adapted for data workflows
AI-Era Additions:
- Machine learning fundamentals (not necessarily building models, but understanding requirements)
- Feature engineering techniques and feature store implementation
- Vector databases for embedding storage and similarity search
- LLM integration for building AI powered data applications
- Model deployment and serving infrastructure
- Data ethics and responsible AI practices
Soft Skills:
- Strong communication to translate between technical and business stakeholders
- Product thinking to build data platforms users actually want
- Collaboration with data scientists, analysts, and software engineers
- Adaptability to rapidly evolving technologies and best practices
For those looking to enhance their technical foundation, understanding DevOps best practices has become increasingly important as data engineering adopts similar methodologies.
Architectural Patterns for AI Ready Data Infrastructure
From Data Warehouses to Data Lakehouses
The lakehouse architecture has emerged as the dominant pattern for AI ready data platforms, combining the best of data lakes and warehouses:
Key Characteristics:
- Open formats (Parquet, ORC) with ACID transactions (Delta Lake, Iceberg)
- Unified storage for structured, semi structured, and unstructured data
- Direct ML framework access without copying data to separate systems
- Schema evolution and time travel capabilities
- Cost effective storage with performance comparable to warehouses
This architecture enables data engineers to support both traditional BI analytics and advanced AI use cases from a single platform.
Data Mesh: Decentralizing Data Ownership
Data mesh principles are reshaping how large organizations structure data teams:
Four Core Principles:
- Domain oriented ownership Data is owned by the teams that generate it
- Data as a product Each domain treats their data as a product with SLAs
- Self serve data platform Central platform team provides tools and infrastructure
- Federated computational governance Automated policies ensure compliance
Data engineers in a mesh architecture focus on building platforms that enable domain teams to publish, discover, and consume data products independently.
Event Driven Architectures for Real Time AI
Modern applications increasingly require real time data processing to power AI features:
Architecture Components:
- Event streaming platforms (Kafka, Pulsar) as the central nervous system
- Stream processing engines (Flink, Spark Streaming) for real time transformations
- Event stores capturing complete event history for model training
- Change Data Capture (CDC) syncing operational databases to analytical systems
- Real time feature computation serving ML models with fresh data
This pattern enables use cases like fraud detection, personalized recommendations, and predictive maintenance that require sub-second response times.
Vector Databases and Semantic Search
The rise of embeddings and generative AI has created demand for specialized storage:
Vector Database Capabilities:
- Store high-dimensional embeddings from ML models
- Perform similarity searches across millions of vectors
- Power semantic search, recommendation systems, and RAG (Retrieval Augmented Generation)
- Examples: Pinecone, Weaviate, Milvus, pgvector
Data engineers now incorporate vector databases alongside traditional relational and NoSQL systems, creating hybrid architectures that support diverse AI workloads.
Big Data Meets AI: Handling Scale and Complexity
The Volume Challenge
Modern organizations generate data at staggering scales. A single large enterprise might process:
- Petabytes of log data daily from applications and infrastructure
- Billions of events from IoT sensors and mobile devices
- Millions of images and videos requiring processing and analysis
- Terabytes of transactional data from operational systems
Data engineers build systems that can:
- Ingest data at rates exceeding 10 million events per second
- Process batch workloads spanning petabytes in hours
- Maintain sub-second query performance on trillion row tables
- Train ML models on datasets too large for single machine memory
Optimizing for AI Workloads
AI and ML introduce unique performance requirements that differ from traditional analytics:
Data Access Patterns:
- Random access to individual records for model inference
- Sequential scanning of massive datasets for model training
- Repeated access to the same features across multiple models
- High throughput writes for real time feature updates
Optimization Techniques:
- Data partitioning by features commonly used together
- Columnar storage for efficient feature extraction
- Caching layers for frequently accessed training data
- GPU-optimized formats (like Apache Arrow) for ML frameworks
- Data versioning to ensure reproducible model training
Understanding how to integrate DevOps with cloud services helps data engineers implement these optimizations effectively.
Cost Management at Scale
Processing big data for AI can become prohibitively expensive without careful engineering.
Cost Optimization Strategies:
Compute:
- Use spot preemptible instances for fault tolerant batch jobs (60-90% cost reduction)
- Right size clusters based on actual workload requirements
- Implement auto scaling to match resource allocation to demand
- Leverage serverless options for sporadic workloads
Storage:
- Implement data lifecycle policies (hot → warm → cold → archive)
- Use compression and efficient file formats (Parquet vs CSV can be 10x smaller)
- Deduplicate redundant data across systems
- Archive or delete data that no longer provides value
Data Transfer:
- Minimize cross region and cross cloud data movement
- Use CDNs and edge caching for frequently accessed data
- Batch operations to reduce API call costs
- Implement data locality principles in distributed processing
The Human Side: Building AI Literate Data Teams
Bridging the Skills Gap
The rapid evolution of data engineering creates both opportunities and challenges for teams.
Upskilling Existing Engineers:
- Provide dedicated learning time (20% time for professional development)
- Create internal training programs on AI/ML fundamentals
- Sponsor certifications in cloud platforms and ML tools
- Encourage experimentation with new technologies in sandbox environments
Hiring for AI-Era Roles:
- Look beyond traditional computer science backgrounds
- Value practical experience with modern data stacks
- Assess problem solving ability over specific tool knowledge
- Prioritize candidates who demonstrate continuous learning
Building Cross Functional Collaboration:
- Embed data engineers within product teams
- Create shared ownership of data quality between engineering and data science
- Establish regular knowledge sharing sessions across disciplines
- Use common tools and platforms to reduce friction
Fostering a Data Driven Culture
Technology alone doesn’t create successful AI initiatives. Data engineers play a crucial role in cultivating organizational data literacy.
Democratizing Data Access:
- Build self-service platforms that don’t require engineering support
- Create comprehensive documentation and data catalogs
- Implement role based access controls that balance security and usability
- Provide training on how to interpret and use data responsibly
Establishing Data Governance:
- Define clear data ownership and stewardship roles
- Implement automated data quality monitoring
- Create feedback loops for data consumers to report issues
- Balance governance with agility (avoid bureaucracy that slows innovation)
Ethical Considerations in AI Powered Data Engineering
Data Privacy and Security
As data engineers build systems that power AI applications, privacy and security responsibilities intensify.
Privacy Preserving Techniques:
- Differential privacy adding noise to protect individual records
- Federated learning training models without centralizing sensitive data
- Data minimization collecting only what’s necessary for specific purposes
- Anonymization and pseudonymization removing personally identifiable information
- Encryption at rest and in transit for all sensitive data
Compliance Frameworks:
- GDPR (Europe), CCPA (California), and emerging regulations worldwide
- Right to deletion and data portability requirements
- Consent management and purpose limitation
- Regular privacy impact assessments for AI systems
Bias Detection and Mitigation
AI models inherit biases present in training data. Data engineers must:
Monitor for Bias:
- Track demographic representation in datasets
- Measure model performance across different population segments
- Implement fairness metrics (demographic parity, equalized odds)
- Create dashboards showing bias indicators over time
Mitigate Bias:
- Oversample underrepresented groups in training data
- Apply fairness constraints during model training
- Use synthetic data generation to balance datasets
- Regularly audit data collection processes for systemic bias
Responsible AI Infrastructure
Building ethical AI requires intentional architectural choices.
Explainability and Transparency:
- Maintain complete data lineage from source to model prediction
- Log all transformations applied to data
- Enable model interpretability through feature importance tracking
- Document assumptions and limitations of datasets
Human Oversight:
- Implement human in-the-loop systems for high stakes decisions
- Create escalation paths when model confidence is low
- Allow users to contest automated decisions
- Regular audits of AI system outcomes
The transformation of modern businesses through AI depends on data engineers implementing these ethical safeguards from the ground up.
Real World Success Stories: AI Driven Data Engineering in Action
Netflix: Personalization at Scale
Netflix processes over 500 billion events daily to power its recommendation engine. Their data engineering achievements include:
- Real time feature computation serving 230+ million subscribers
- A/B testing infrastructure running thousands of experiments simultaneously
- Custom data platform (Metacat) unifying metadata across diverse storage systems
- Automated data quality monitoring preventing bad data from reaching models
Impact: Personalized recommendations drive 80% of content watched, saving billions in customer acquisition costs.
Uber: Real Time Decision Making
Uber’s data platform handles 100 petabytes of data and supports real time applications like dynamic pricing and driver-rider matching:
- Michelangelo feature store serving features with <10ms latency
- Apache Pinot for real time analytics on streaming data
- Automated ML pipeline deploying thousands of models
- Multi region data replication ensuring global availability
Impact: Real time pricing adjusts to demand every few seconds, optimizing marketplace efficiency.
Spotify: Understanding User Intent
Spotify’s data engineers built infrastructure supporting 500+ ML models that power discovery and personalization:
- Event delivery platform processing 10 million events per second
- Feature store enabling rapid experimentation by data scientists
- Automated model deployment reducing time to production from weeks to hours
- Privacy preserving analytics protecting user listening data
Impact: Personalized playlists like Discover Weekly engage 40% of users weekly, driving retention.
These examples demonstrate how AI is driving innovation across industries through sophisticated data engineering.
Future Trends: What’s Next for Data Engineering?
1. Autonomous Data Platforms
The next frontier is self managing data infrastructure that requires minimal human intervention:
- AI agents that automatically optimize queries and data layouts
- Self healing pipelines that detect and fix failures
- Adaptive systems that adjust to changing data patterns
- Natural language interfaces for platform configuration
Timeline: Early implementations emerging in 2025-2026, mainstream adoption by 2028.
2. Edge Computing and Distributed AI
As AI moves to edge devices (phones, IoT sensors, vehicles), data engineering must evolve:
- Federated data processing across distributed devices
- Efficient data synchronization between edge and cloud
- Privacy preserving aggregation of edge-generated data
- Low latency feature serving for edge ML models
Timeline: Accelerating rapidly with 5G adoption and specialized AI chips.
3. Quantum Ready Data Architecture
While practical quantum computing remains years away, forward thinking organizations are preparing:
- Data structures optimized for quantum algorithms
- Hybrid classical quantum processing pipelines
- Quantum resistant encryption for long term data security
- Simulation environments for quantum algorithm development
Timeline: Experimental phase in 2025-2027, practical applications post-2030.
4. Sustainable Data Engineering
Environmental impact of data processing is driving green engineering practices:
- Carbon aware job scheduling (running workloads when renewable energy is available)
- Optimization for energy efficiency, not just performance
- Data lifecycle management reducing unnecessary storage
- Measurement and reporting of data infrastructure carbon footprint
Timeline: Becoming a priority in 2025, with regulatory requirements likely by 2027.
5. Convergence of Data Engineering and Software Engineering
The boundaries between disciplines continue to blur:
- Data engineers adopting software engineering practices (testing, CI/CD, code review)
- Software engineers incorporating data awareness into application design
- Unified platforms serving both operational and analytical workloads
- Common tooling and languages across disciplines
Timeline: Already underway, accelerating through 2025-2027.
Getting Started: Your Path to AI Era Data Engineering
For Aspiring Data Engineers
If you’re looking to enter the field, here’s a practical roadmap:
Month 1-3: Build Foundations
- Learn Python (focus on Pandas, NumPy, data manipulation)
- Master SQL (joins, window functions, CTEs, optimization)
- Understand database fundamentals (relational vs NoSQL)
- Complete online courses (DataCamp, Coursera, Udacity)
Month 4-6: Cloud and Distributed Systems
- Get certified in one cloud platform (AWS, GCP, or Azure)
- Learn Apache Spark basics
- Build projects using cloud data services
- Contribute to open-source data tools
Month 7-9: Modern Data Stack
- Learn data orchestration (start with Airflow)
- Explore dbt for analytics engineering
- Understand streaming concepts with Kafka
- Build an end to end data pipeline project
Month 10-12: AI/ML Integration
- Take ML fundamentals course
- Learn feature engineering techniques
- Deploy a simple ML model to production
- Explore MLOps tools and practices
Portfolio Projects:
- Build a real time dashboard using streaming data
- Create a data quality monitoring system
- Deploy an ML model with automated retraining
- Contribute to open source data engineering projects
For Experienced Engineers Transitioning to Data
Leverage your existing skills while filling data-specific gaps.
Your Advantages:
- Strong programming fundamentals
- Software engineering best practices (testing, CI/CD, version control)
- System design and architecture experience
- Problem solving and debugging skills
Focus Areas:
- SQL and data modeling (different mindset than application development)
- Distributed data processing (Spark, data-parallel thinking)
- Data specific tools and frameworks
- Understanding of analytical vs operational workloads
Transition Strategy:
- Take on data adjacent projects in your current role
- Partner with data teams to understand their challenges
- Build internal data tools or platforms
- Pursue data engineering roles at companies valuing software engineering skills
For Data Engineers Upskilling for AI
If you’re already in data engineering but want to stay current:
Priority Skills:
- Machine learning fundamentals (you don’t need to be a data scientist, but understand the workflow)
- Feature engineering and feature stores
- Model deployment and serving infrastructure
- Real time data processing for ML inference
- Data quality for ML (different requirements than BI)
Learning Approach:
- Partner with data scientists on production ML projects
- Rebuild existing batch ML pipelines as real-time systems
- Implement MLOps practices in your organization
- Experiment with LLMs and generative AI applications
Certifications to Consider:
- AWS Certified Machine Learning Specialty
- Google Professional Machine Learning Engineer
- Databricks Certified Data Engineer Professional
- Snowflake SnowPro Advanced: Data Engineer
For those looking to deepen their understanding of modern practices, exploring DevOps in cloud environments provides valuable insights applicable to data engineering.
Building Your Data Engineering Career in 2025
Choosing Your Specialization
The breadth of data engineering means specialization often leads to deeper expertise and higher compensation.
Analytics Engineering Best for those who:
- Enjoy working closely with business stakeholders
- Excel at SQL and data modeling
- Want to directly impact business decisions
- Prefer structured, well defined problems
ML/AI Engineering Best for those who:
- Are excited by cutting edge technology
- Enjoy mathematical and algorithmic thinking
- Want to build intelligent systems
- Thrive in ambiguous, research oriented environments
Platform Engineering Best for those who:
- Love building tools others use
- Have strong software engineering backgrounds
- Enjoy solving infrastructure challenges
- Want to enable entire organizations
Streaming Real Time Best for those who:
- Are passionate about low-latency systems
- Enjoy performance optimization
- Like working with event driven architectures
- Thrive under operational pressure
Compensation and Job Market
The data engineering job market in 2025 is extremely favorable for qualified candidates.
Salary Ranges (US Market):
- Entry-level (0-2 years): $90,000 – $130,000
- Mid-level (3-5 years): $130,000 – $180,000
- Senior (6-10 years): $180,000 – $250,000
- Staff/Principal (10+ years): $250,000 – $400,000+
- FAANG companies: Add 20-40% premium
Beyond Base Salary:
- Equity stock options (can double total compensation at startups and tech companies)
- Annual bonuses (10-20% of base)
- Remote work flexibility (65% of roles)
- Professional development budgets
- Conference attendance and speaking opportunities
Geographic Considerations:
- Remote work has globalized opportunities
- Cost of living adjustments vary by company
- Major tech hubs (SF, NYC, Seattle) still command premiums
- Emerging hubs (Austin, Denver, Miami) growing rapidly
Companies Hiring Data Engineers
Tech Giants:
- Google, Amazon, Microsoft, Meta, Apple
- Focus on massive scale and cutting edge AI
- Highly competitive, rigorous interview processes
- Excellent compensation and learning opportunities
AI First Companies:
- OpenAI, Anthropic, Databricks, Snowflake
- Building the future of AI infrastructure
- Fast paced, research oriented cultures
- Significant equity upside potential
Data Platform Vendors:
- Confluent, dbt Labs, Fivetran, Airbyte
- Build tools other data engineers use
- Deep technical focus
- Impact the entire industry
Traditional Enterprises:
- Banks, healthcare, retail, manufacturing
- Undergoing digital transformation
- Opportunity to build from scratch
- Often more work-life balance
Startups:
- High growth potential and responsibility
- Wear multiple hats
- Significant equity stakes
- Higher risk, higher reward
To understand how companies are leveraging these capabilities, explore real-world applications of AI in business.
Conclusion: Embracing the AI-Powered Future of Data Engineering
Data engineering stands at the intersection of the most transformative technologies of our time. The convergence of big data, cloud computing, and artificial intelligence has created a discipline that is simultaneously more complex and more impactful than ever before.
The data engineers of 2025 are not merely moving data from point A to point B they are architects of intelligence, building the foundations upon which AI systems learn, adapt, and deliver value. They are guardians of quality and ethics, ensuring that automated decisions are fair, transparent, and accountable. They are enablers of innovation, creating platforms that democratize data access and accelerate experimentation.