In today’s data-driven world, organizations generate massive amounts of information every second. Yet, raw data alone is worthless; it’s like having a gold mine without the tools to extract the precious metal. This is where data engineering becomes the backbone of modern business intelligence, transforming chaotic data streams into structured, accessible assets that power everything from machine learning models to executive dashboards.
As companies increasingly rely on big data to drive strategic decisions, the demand for skilled data engineers has skyrocketed. These professionals build the critical infrastructure that enables data scientists, analysts, and business leaders to extract meaningful insights from petabytes of information. Understanding data engineering is no longer optional for organizations seeking competitive advantage it’s essential.
What is Data Engineering?
Data engineering is the discipline of designing, constructing, and managing the architecture, infrastructure, and systems that enable organizations to collect, store, process, and analyze massive volumes of data. Think of data engineers as the architects and builders of data highways they create the robust pathways that allow information to flow smoothly from various sources to end users.
At its core, data engineering focuses on making data accessible, reliable, and ready for analysis. While data scientists focus on extracting insights and building models, data engineers ensure there’s clean, well organized data available for them to work with. This foundational work is critical because even the most sophisticated analytical algorithms are useless without quality data feeding them.
The Evolution of Data Engineering
The field has evolved dramatically over the past two decades. In the early 2000s, traditional database administrators handled most data-related tasks using relational databases and batch processing. However, the explosion of big data characterized by the three Vs of volume, velocity, and variety necessitated entirely new approaches.
Modern data engineering emerged to address these challenges, incorporating distributed systems, real time processing, and cloud-native architectures. Today’s data engineers work with technologies that can process terabytes of data in minutes, handle streaming data from millions of IoT devices, and integrate structured and unstructured data from countless sources.
Data Engineering vs. Related Roles
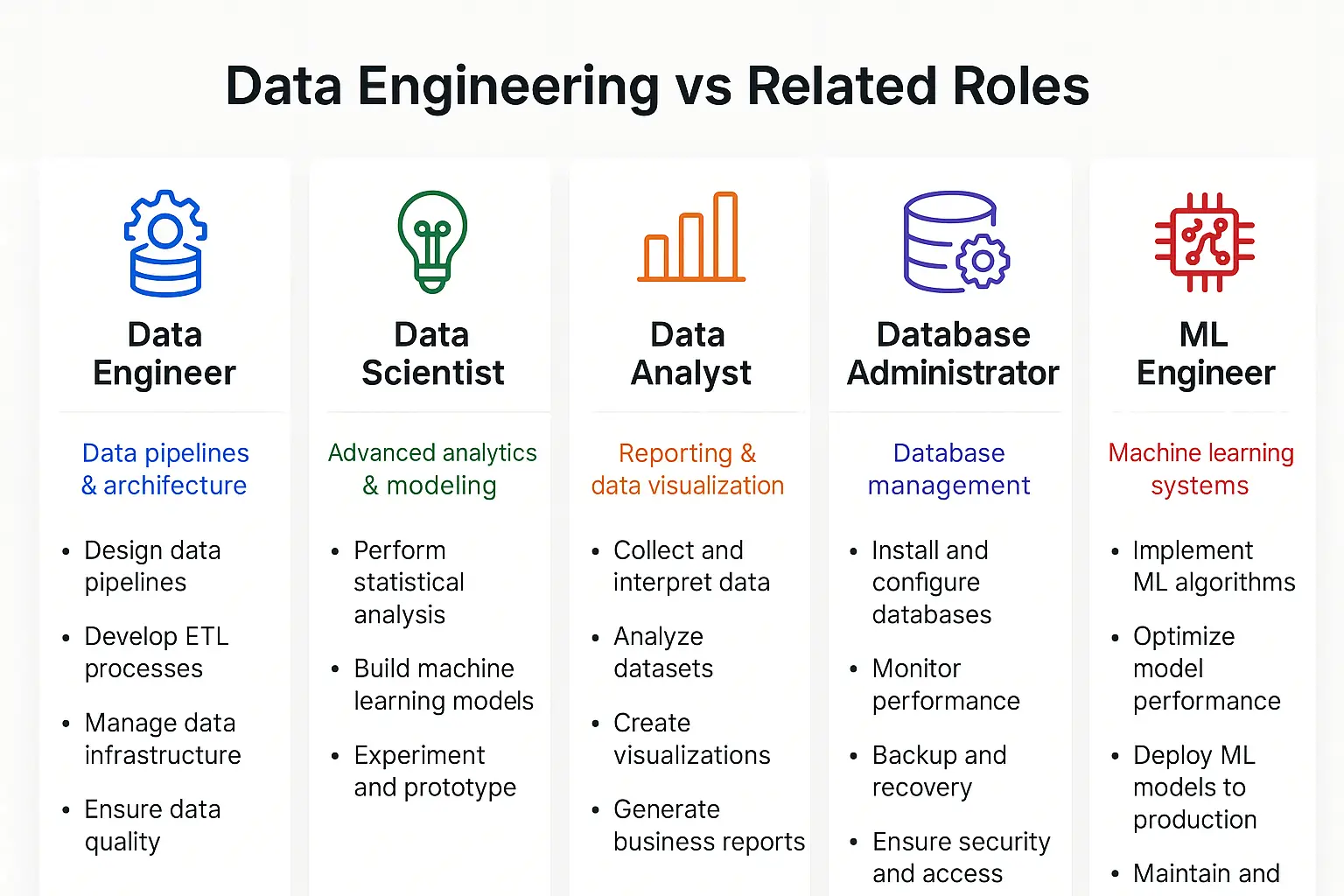
Understanding how data engineering differs from related disciplines helps clarify its unique value:
| Role | Primary Focus | Key Deliverables |
|---|---|---|
| Data Engineer | Building data infrastructure and pipelines | ETL systems, data warehouses, data lakes |
| Data Scientist | Extracting insights and building models | Predictions, recommendations, statistical analyses |
| Data Analyst | Interpreting data and reporting | Dashboards, reports, business insights |
| Database Administrator | Managing database systems | Database performance, security, backups |
| ML Engineer | Deploying machine learning models | Production ML systems, model optimization |
Core Responsibilities of Data Engineers
Data engineers wear many hats, handling diverse responsibilities that keep the data ecosystem functioning smoothly. These responsibilities have expanded significantly as organizations embrace more sophisticated data strategies.
Building and Maintaining Data Pipelines
The most fundamental responsibility is designing and implementing data pipelines automated workflows that move data from source systems to destinations where it can be analyzed. These pipelines must be:
- Reliable: Running consistently without failures
- Scalable: Handling growing data volumes
- Efficient: Processing data quickly and cost-effectively
- Maintainable: Easy to update and troubleshoot
A typical pipeline might extract data from customer databases, transform it by cleaning and standardizing formats, and load it into a data warehouse the classic ETL (Extract, Transform, Load) process. Modern approaches also include ELT (Extract, Load, Transform), where raw data is loaded first and transformed within the destination system.
Designing Data Architecture
Data engineers architect the overall data ecosystem, making critical decisions about:
- Storage solutions: Choosing between data warehouses, data lakes, or hybrid approaches
- Processing frameworks: Selecting batch processing, stream processing, or both
- Integration patterns: Determining how different systems communicate
- Scalability strategies: Planning for future growth
These architectural decisions have long-term implications for performance, costs, and capabilities. A well designed architecture enables artificial intelligence and machine learning initiatives to thrive.
Ensuring Data Quality and Governance
Data quality is paramount garbage in, garbage out. Data engineers implement:
- Validation rules: Checking data accuracy and completeness
- Data cleansing: Removing duplicates and correcting errors
- Schema enforcement: Maintaining consistent data structures
- Monitoring systems: Detecting quality issues proactively
They also support data governance initiatives by implementing access controls, audit trails, and compliance measures that protect sensitive information and meet regulatory requirements.
Optimizing Performance
As data volumes grow, performance optimization becomes critical. Data engineers continuously work to:
- Improve query response times
- Reduce processing costs
- Optimize storage efficiency
- Minimize data transfer latency
This involves techniques like partitioning, indexing, caching, and choosing appropriate compression algorithms. Similar to DevOps best practices, data engineers must balance performance, reliability, and cost.
Enabling Real Time Analytics
Many modern applications require real time data processing from fraud detection to personalized recommendations. Data engineers build streaming architectures that:
- Ingest data from sources like IoT sensors, clickstreams, and transaction systems
- Process events in milliseconds or seconds
- Deliver insights to applications immediately
- Handle millions of events per second
Collaboration and Documentation
Data engineers work closely with multiple stakeholders:
- Data scientists: Providing clean datasets for analysis
- Business analysts: Creating accessible reporting structures
- Software developers: Integrating data systems with applications
- Leadership: Explaining technical capabilities and limitations
Comprehensive documentation ensures knowledge transfer and system maintainability, especially as teams grow and evolve.
Essential Data Engineering Skills
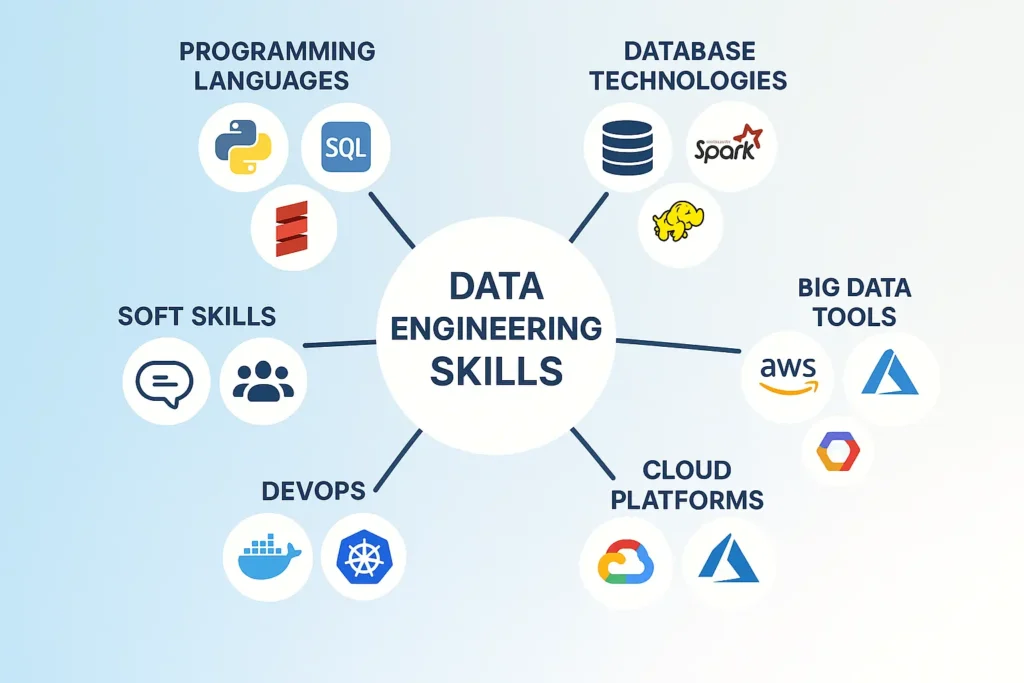
Becoming a proficient data engineer requires mastering a diverse skill set spanning programming, databases, distributed systems, and cloud technologies.
Programming Languages
Python has emerged as the dominant language for data engineering due to its extensive libraries and readability. Key Python frameworks include:
- Pandas: Data manipulation and analysis
- PySpark: Distributed data processing
- Airflow: Workflow orchestration
- SQLAlchemy: Database interaction
SQL remains absolutely essential data engineers spend significant time writing complex queries, optimizing joins, and managing database objects. Advanced SQL skills include window functions, CTEs (Common Table Expressions), and query optimization.
Other valuable languages include:
- Scala: Often used with Apache Spark
- Java: For enterprise big data systems
- Bash/Shell scripting: Automation and system administration
Database Technologies
Data engineers must understand both relational and NoSQL databases:
Relational Databases (SQL):
- PostgreSQL
- MySQL
- Oracle
- Microsoft SQL Server
NoSQL Databases:
- Document stores: MongoDB, Couchbase
- Column family stores: Cassandra, HBase
- Key value stores: Redis, DynamoDB
- Graph databases: Neo4j, Amazon Neptune
Each database type serves different use cases, and skilled engineers know when to apply each technology.
Big Data Technologies and Frameworks
The big data ecosystem includes numerous specialized tools:
Apache Hadoop Ecosystem:
- HDFS: Distributed file storage
- MapReduce: Distributed processing framework
- Hive: SQL like queries on Hadoop
- Pig: Data flow scripting language
Apache Spark:
The most popular big data processing framework, offering:
- Batch processing
- Stream processing (Spark Streaming)
- Machine learning (MLlib)
- Graph processing (GraphX)
Stream Processing:
- Apache Kafka: Distributed event streaming
- Apache Flink: Stream and batch processing
- Amazon Kinesis: Cloud-based streaming
Cloud Platforms
Cloud expertise is increasingly mandatory as organizations migrate to cloud-based data infrastructure. The major platforms offer comprehensive data services:
Amazon Web Services (AWS):
- S3: Object storage
- Redshift: Data warehouse
- EMR: Managed Hadoop/Spark
- Glue: ETL service
- Athena: Serverless queries
Google Cloud Platform (GCP):
- BigQuery: Serverless data warehouse
- Dataflow: Stream and batch processing
- Cloud Storage: Object storage
- Pub/Sub: Messaging service
Microsoft Azure:
- Azure Synapse Analytics: Unified analytics
- Azure Data Lake: Scalable storage
- Azure Databricks: Apache Spark platform
- Azure Data Factory: ETL/ELT service
Understanding cloud based DevOps practices enhances a data engineer’s ability to build robust, scalable systems.
Data Modeling and Warehousing
Strong data modeling skills enable engineers to design efficient database schemas. Key concepts include:
- Dimensional modeling: Star and snowflake schemas for analytics
- Normalization: Reducing redundancy in transactional systems
- Data vault: Modeling for data warehouses
- Schema design: Choosing appropriate structures for NoSQL databases
DevOps and DataOps
Modern data engineers embrace DataOps principles, applying DevOps methodologies to data workflows:
- Version control (Git)
- Continuous integration/continuous deployment (CI/CD)
- Infrastructure as code (Terraform, CloudFormation)
- Containerization (Docker, Kubernetes)
- Monitoring and alerting
These practices, similar to DevOps in cloud environments, improve reliability and deployment speed.
Soft Skills
Technical prowess alone isn’t enough. Successful data engineers also possess:
- Problem solving: Debugging complex distributed systems
- Communication: Explaining technical concepts to non technical stakeholders
- Collaboration: Working effectively in cross functional teams
- Continuous learning: Keeping pace with rapidly evolving technologies
- Business acumen: Understanding how data supports organizational goals
The Data Engineering Workflow
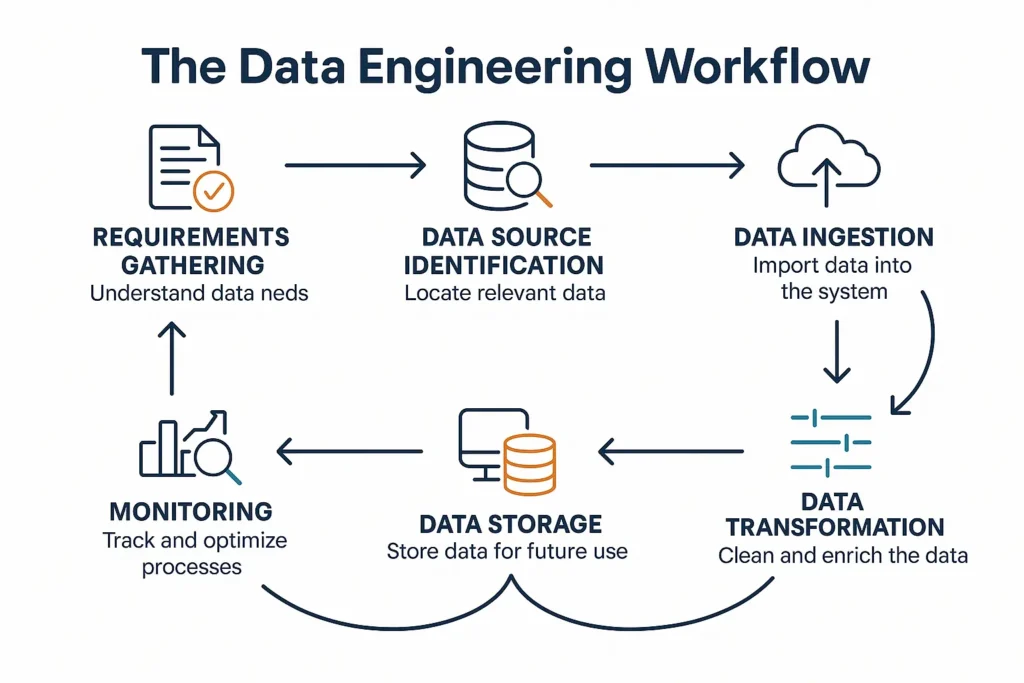
Understanding the typical workflow helps clarify how data engineers spend their time and deliver value.
Step 1: Requirements Gathering
Data engineers begin by understanding business needs:
- What questions need answering?
- What data sources are available?
- What are the latency requirements?
- What volume of data is expected?
- What compliance requirements exist?
Step 2: Data Source Identification and Integration
Next, they identify and connect to relevant data sources:
- Transactional databases
- APIs and web services
- Log files and event streams
- Third-party data providers
- IoT devices and sensors
Integration often involves building connectors, handling authentication, and managing rate limits.
Step 3: Data Ingestion
Data must be reliably moved from sources to processing systems. Engineers choose appropriate ingestion patterns:
- Batch ingestion: Periodic loads (hourly, daily, weekly)
- Micro batch: Frequent small batches
- Real time streaming: Continuous data flow
- Change data capture (CDC): Tracking database changes
Step 4: Data Transformation
Raw data rarely arrives in analysis-ready format. Transformation includes:
- Cleaning: Removing errors and inconsistencies
- Standardization: Applying consistent formats and units
- Enrichment: Adding calculated fields or external data
- Aggregation: Summarizing detailed data
- Joining: Combining data from multiple sources
Step 5: Data Storage
Transformed data is stored in appropriate systems:
- Data warehouses: Optimized for analytics queries
- Data lakes: Storing raw and processed data at scale
- Data marts: Subject-specific subsets for departments
- Operational data stores: Supporting real-time applications
Step 6: Data Serving
Finally, data is made available to consumers:
- Creating views and tables for analysts
- Building APIs for applications
- Generating reports and dashboards
- Feeding machine learning pipelines
- Enabling self-service analytics
Step 7: Monitoring and Maintenance
Ongoing responsibilities include:
- Monitoring pipeline health and performance
- Investigating and resolving failures
- Optimizing slow queries and processes
- Updating schemas as requirements change
- Managing capacity and costs
Big Data and Its Impact on Data Engineering
The rise of big data has fundamentally transformed data engineering practices and requirements. Understanding this evolution is crucial for appreciating modern data engineering.
What Defines Big Data?
Big data is typically characterized by the “Three Vs”:
- Volume: Massive amounts of data (terabytes to petabytes)
- Velocity: High-speed data generation and processing needs
- Variety: Diverse data types (structured, semi-structured, unstructured)
Additional Vs sometimes include:
- Veracity: Data quality and trustworthiness
- Value: The business benefit extracted from data
Organizations today generate unprecedented data volumes. A single autonomous vehicle can produce 4 terabytes of data daily. Social media platforms process billions of interactions hourly. E-commerce sites track millions of customer behaviors continuously.
Big Data Technologies and Architecture
Traditional databases and processing tools couldn’t handle big data’s scale, leading to new technologies:
Distributed Storage:
- Spreading data across multiple servers
- Providing redundancy and fault tolerance
- Enabling parallel access
Distributed Processing:
- Breaking computations into smaller tasks
- Executing tasks across multiple nodes
- Aggregating results
Horizontal Scaling:
- Adding more machines rather than upgrading existing ones
- Providing cost-effective scalability
- Supporting elastic capacity
Real World Big Data Applications
Big data applications span numerous industries:
Retail and E commerce:
- Personalized product recommendations
- Dynamic pricing optimization
- Inventory forecasting
- Customer behavior analysis
Healthcare:
- Predictive diagnostics
- Treatment optimization
- Population health management
- Drug discovery
Finance:
- Fraud detection
- Risk assessment
- Algorithmic trading
- Customer segmentation
Manufacturing:
- Predictive maintenance
- Quality control
- Supply chain optimization
- Production efficiency
Telecommunications:
- Network optimization
- Customer churn prediction
- Service personalization
- Infrastructure planning
These applications often leverage AI and generative AI technologies built on robust data engineering foundations.
Challenges in Big Data Engineering
Working with big data introduces unique challenges:
Complexity: Distributed systems are inherently more complex than single-server solutions, requiring sophisticated error handling and coordination.
Data Quality: With more data sources comes greater inconsistency. Ensuring quality at scale requires automated validation and cleansing.
Cost Management: Storing and processing petabytes of data is expensive. Engineers must optimize resource usage continuously.
Security and Privacy: More data means more risk. Protecting sensitive information while enabling analytics requires careful architecture.
Skill Requirements: The learning curve for big data technologies is steep, creating talent shortages in many organizations.
Career Path and Opportunities in Data Engineering
Data engineering offers exciting career prospects with strong growth projections and competitive compensation.
Entry Level Positions
Aspiring data engineers often start as:
- Junior Data Engineer: Learning pipelines and basic ETL
- Data Analyst: Gaining SQL and data understanding
- Database Developer: Building database skills
- ETL Developer: Focusing on data integration
Entry level positions typically require:
- Bachelor’s degree in Computer Science, Information Systems, or related field
- Strong SQL skills
- Basic programming knowledge (Python or Java)
- Understanding of database concepts
- Internship or project experience
Mid-Level Positions
With 2-5 years of experience, engineers advance to:
- Data Engineer: Building and maintaining production pipelines
- Analytics Engineer: Bridging data engineering and analytics
- Big Data Engineer: Specializing in distributed systems
- Cloud Data Engineer: Focusing on cloud platforms
Mid-level engineers should demonstrate:
- Proficiency in multiple programming languages
- Experience with big data frameworks
- Cloud platform expertise
- Data modeling skills
- Pipeline orchestration knowledge
Senior and Leadership Roles
Experienced professionals move into:
- Senior Data Engineer: Leading complex projects and mentoring juniors
- Lead Data Engineer: Managing technical direction for teams
- Data Architect: Designing enterprise data strategies
- Data Engineering Manager: Overseeing engineering teams
- Head of Data Engineering: Setting organizational data engineering strategy
Senior roles require:
- 5+ years of relevant experience
- Deep technical expertise across multiple technologies
- Architectural design capabilities
- Leadership and communication skills
- Strategic thinking and business acumen
Salary Expectations in 2025
Data engineering compensation remains highly competitive:
United States:
- Entry-level: $75,000 – $105,000
- Mid-level: $105,000 – $150,000
- Senior: $150,000 – $220,000
- Lead/Principal: $200,000 – $300,000+
Factors Affecting Compensation:
- Geographic location (higher in tech hubs)
- Company size and industry
- Specific technical skills (cloud certifications, Spark expertise)
- Education level (advanced degrees often command premiums)
- Total compensation including stock options and bonuses
Industry Demand
Demand for data engineers continues growing rapidly:
- LinkedIn listed data engineering among the fastest growing jobs
- The U.S. Bureau of Labor Statistics projects strong growth through 2030
- Companies across all sectors are investing heavily in data capabilities
- Remote work opportunities have expanded the talent pool
Industries with particularly high demand include:
- Technology and software
- Financial services
- Healthcare and pharmaceuticals
- Retail and e-commerce
- Telecommunications
- Manufacturing
Certifications and Continuous Learning
Professional certifications can accelerate career growth:
Cloud Certifications:
- AWS Certified Data Analytics
- Google Professional Data Engineer
- Microsoft Certified: Azure Data Engineer Associate
Technology-Specific:
- Databricks Certified Associate Developer
- Cloudera Certified Professional (CCP) Data Engineer
- MongoDB Certified Developer
General:
- Data Management Professional (CDMP)
Continuous learning is essential given rapid technological change. Data engineers should:
- Follow industry blogs and publications
- Participate in online communities
- Attend conferences and webinars
- Experiment with new technologies
- Contribute to open source projects
Data Engineering Best Practices
Implementing best practices ensures reliable, efficient, and maintainable data systems.
Design for Scalability from Day One
Build systems that can grow with data volumes:
- Use distributed architectures when appropriate
- Implement partitioning strategies early
- Choose technologies that scale horizontally
- Plan for 10x current data volumes
Implement Robust Error Handling
Data pipelines will fail design for resilience:
- Add comprehensive logging and monitoring
- Implement retry logic with exponential backoff
- Design idempotent operations (safe to retry)
- Create alerting for critical failures
- Build rollback capabilities
Prioritize Data Quality
Quality should be built into every pipeline:
- Validate data at ingestion
- Implement schema enforcement
- Create data quality metrics and dashboards
- Establish data quality SLAs
- Document data lineage
Embrace Automation
Automate repetitive tasks:
- Use infrastructure as code
- Implement CI/CD for data pipelines
- Automate testing and validation
- Schedule routine maintenance tasks
- Create self healing systems where possible
Document Thoroughly
Good documentation saves countless hours:
- Document data schemas and transformations
- Create runbooks for common issues
- Maintain architecture diagrams
- Write clear code comments
- Keep documentation updated
Optimize for Cost
Cloud costs can spiral quickly:
- Right-size compute resources
- Use appropriate storage tiers
- Implement data lifecycle policies
- Monitor and analyze spending
- Delete unused resources
Ensure Security and Compliance
Protect sensitive data:
- Implement least-privilege access
- Encrypt data at rest and in transit
- Audit data access
- Comply with regulations (GDPR, HIPAA, etc.)
- Anonymize or pseudonymize when appropriate
Version Control Everything
Treat infrastructure and code equally:
- Version control all pipeline code
- Track infrastructure changes
- Maintain change logs
- Enable rollback capabilities
- Use branching strategies
Future Trends in Data Engineering
The field continues evolving rapidly. Key trends shaping the future include:
Serverless Data Processing
Serverless architectures eliminate infrastructure management:
- Pay only for actual usage
- Automatic scaling
- Reduced operational overhead
- Examples: AWS Lambda, Google Cloud Functions
Real-Time Everything
Batch processing is giving way to streaming:
- Immediate insights from data
- Event-driven architectures
- Stream processing becoming standard
- Reduced latency requirements
DataOps Maturation
DataOps practices are becoming mainstream:
- Automated testing for data pipelines
- Continuous deployment of data workflows
- Collaborative development practices
- Monitoring and observability improvements
AI-Assisted Data Engineering
Artificial intelligence is enhancing data engineering:
- Automated pipeline generation
- Intelligent data quality detection
- Self optimizing queries
- Anomaly detection in data flows
Generative AI applications are also creating new data engineering challenges and opportunities, requiring systems that can handle diverse content types and massive model training datasets.
Data Mesh Architecture
Decentralized data ownership is gaining traction:
- Domain oriented data ownership
- Data as a product philosophy
- Self service data infrastructure
- Federated governance
Enhanced Privacy Technologies
Privacy-preserving techniques are advancing:
- Differential privacy
- Federated learning
- Homomorphic encryption
- Secure multi party computation
Unified Batch and Streaming
Technologies that handle both paradigms seamlessly:
- Apache Flink
- Apache Beam
- Databricks Delta Lake
- Simplified architectures
Increased Focus on Data Observability
Comprehensive monitoring beyond basic metrics:
- Data quality monitoring
- Schema change detection
- Data freshness tracking
- Lineage visualization
- Anomaly detection
Common Tools and Technologies in the Data Engineering Stack
Modern data engineers work with an extensive toolkit. Here’s a comprehensive overview:
Workflow Orchestration
- Apache Airflow: Most popular open-source orchestrator
- Prefect: Modern alternative with dynamic workflows
- Dagster: Data aware orchestration
- Luigi: Spotify’s workflow manager
- Azure Data Factory: Microsoft’s cloud orchestrator
Data Integration and ETL
- Fivetran: Automated data connectors
- Stitch: Simple pipeline as a service
- Talend: Enterprise ETL platform
- Apache NiFi: Data flow automation
- dbt (data build tool): Transform data in warehouses
Data Quality
- Great Expectations: Data validation framework
- Monte Carlo: Data observability platform
- Soda: Data quality testing
- Apache Griffin: Big data quality solution
Data Catalogs
- Alation: Enterprise data catalog
- Collibra: Data governance platform
- Apache Atlas: Metadata framework
- DataHub: LinkedIn’s open-source catalog
Version Control and Collaboration
- Git/GitHub/GitLab: Code versioning
- Bitbucket: Atlassian’s Git solution
- DVC (Data Version Control): Version control for data
Getting Started in Data Engineering
For those interested in entering the field, here’s a practical roadmap:
Step 1: Build Foundational Knowledge
Start with core concepts:
- Learn SQL thoroughly (practice on platforms like LeetCode, HackerRank)
- Master Python basics and data manipulation (Pandas, NumPy)
- Understand database fundamentals (relational and NoSQL)
- Study basic data structures and algorithms
Step 2: Develop Technical Skills
Progress to intermediate topics:
- Learn a big data framework (start with Spark)
- Gain cloud platform experience (choose AWS, GCP, or Azure)
- Practice building ETL pipelines
- Understand data modeling and warehousing
- Learn Docker and basic DevOps
Step 3: Build Portfolio Projects
Create tangible demonstrations of your skills:
- Build an end to end data pipeline
- Create a real-time streaming application
- Design and implement a data warehouse
- Contribute to open source data projects
- Document projects on GitHub
Step 4: Gain Practical Experience
Apply your knowledge:
- Seek internships or entry level positions
- Take on data-related projects in current role
- Freelance on platforms like Upwork
- Participate in data engineering communities
Step 5: Pursue Certifications
Validate your expertise:
- Start with foundational certifications
- Progress to professional-level credentials
- Focus on in-demand technologies
- Keep certifications current
Step 6: Network and Learn Continuously
Connect with the community:
- Join data engineering communities (Reddit, Slack groups)
- Attend meetups and conferences
- Follow thought leaders on social media
- Read industry blogs and publications
- Share your knowledge through writing or speaking
Conclusion
Data engineering has emerged as one of the most critical disciplines in modern technology, serving as the foundation upon which data-driven organizations build their competitive advantages. As we’ve explored, data engineering encompasses far more than just moving data from point A to point B it requires architecting robust systems, ensuring data quality, optimizing performance, and enabling both batch and real-time analytics at massive scale.
The field demands a unique combination of technical expertise across programming, databases, distributed systems, and cloud platforms, along with soft skills like communication and problem-solving. As organizations continue embracing big data and artificial intelligence, the demand for skilled data engineers will only intensify through 2025 and beyond.For those considering a career in data engineering, the opportunities are exceptional. The role offers intellectual challenge, competitive compensation, and the satisfaction of building systems that drive real business impact. Whether you’re supporting AI-driven innovations, enabling data driven marketing, or powering critical business operations, data engineers play an indispensable role in the modern data ecosystem.